

In previous posts, we have provided examples of how you can perform advanced Pandas operations like Reshape Pandas Data Frames, How to Assign Values Based On Multiple Conditions, How to use Dplyr Pipes in Pandas etc. However, sometimes is more convenient to write a simple SQL query. Below, we will show you how you can easily query Pandas Data Frames using SQL Syntax. If you are familiar with R, the package that we will use is similar to sqldf.
Part A – pandasql
Installation
We will work with the pandasql package and we can download it as follows:
pip install -U pandasqlGenerate Sample Data
We will generate two data frames for exhibition purposes.
import pandas as pd
import numpy as np
from pandasql import sqldf
# set a random seed
np.random.seed(5)
# gender 60% male 30% female 10% unknown
# age from poisson distribution with lambda=25
# score a random integer from 0 to 100
my_df = pd.DataFrame({'gender':np.random.choice(a=['m','f', 'u'], size=20, p=[0.6,0.3, 0.1]),
'age':np.random.poisson(lam=25, size=20),
'score_a':np.random.randint(100, size=20),
'score_b':np.random.randint(100, size=20),
'score_c':np.random.randint(100, size=20)})
gender = pd.DataFrame({'gender':['m','f', 'u'], 'full':['male','female', 'unknown']})
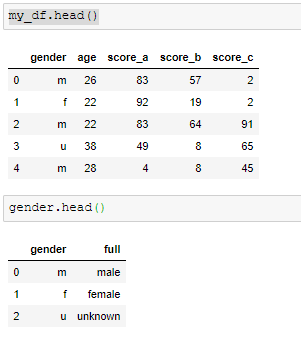
Query Pandas Data Frames with SQL
Let’s see how we can query the data frames.
The main function used in pandasql is sqldf. sqldf accepts 2 parameters
- a sql query string
- a set of session/environment variables (
locals()orglobals())
You can use type the following command to avoid specifying it every time you want to run a query.
from pandasql import sqldf pysqldf = lambda q: sqldf(q, globals())
Let”s get the average score of each column of the my_df data frame by gender as well as the number of observations.
pysqldf("""select Gender, count(*) as obs, avg(age) as avg_age, avg(score_a) as avg_score_a,
avg(score_b) as avg_score_b,
avg(score_c) as avg_score_c
from my_df
group by gender""")

Now let’s say that we want to join this table with the gender table.
pysqldf("""select * from gender
inner join (select Gender, count(*) as obs, avg(age) as avg_age, avg(score_a) as avg_score_a,
avg(score_b) as avg_score_b,
avg(score_c) as avg_score_c
from my_df
group by gender) b
on gender.gender = b.gender""")

Notice that the output is a Pandas Data Frame and it can be stored:
my_output = pysqldf("""select * from gender
inner join (select Gender, count(*) as obs, avg(age) as avg_age, avg(score_a) as avg_score_a,
avg(score_b) as avg_score_b,
avg(score_c) as avg_score_c
from my_df
group by gender) b
on gender.gender = b.gender""")
my_output
Part B – sqldf
We can also work with the sqldf package which is a wrapper to run SQL (SQLite) queries on pandas.DataFrame objects (Python).
Installation
We can install it with:
pip install sqldfand the requirements are:
- ‘python’ >= 3.5
- ‘pandas’ >= 1.0
Query Pandas Data Frames with SQL
Let’s provide the same example as above:
# Import libraries
import pandas as pd
import numpy as np
import sqldf
# Define a SQL (SQLite3) query
query = """
select Gender, count(*) as obs, avg(age) as avg_age, avg(score_a) as avg_score_a,
avg(score_b) as avg_score_b,
avg(score_c) as avg_score_c
from my_df
group by gender
"""
# Run the query
df_view = sqldf.run(query)

Notice that sqldf has an issue with the parenthesis and apparently, you cannot run sub-queries. Feel free to have a look at more examples here


