
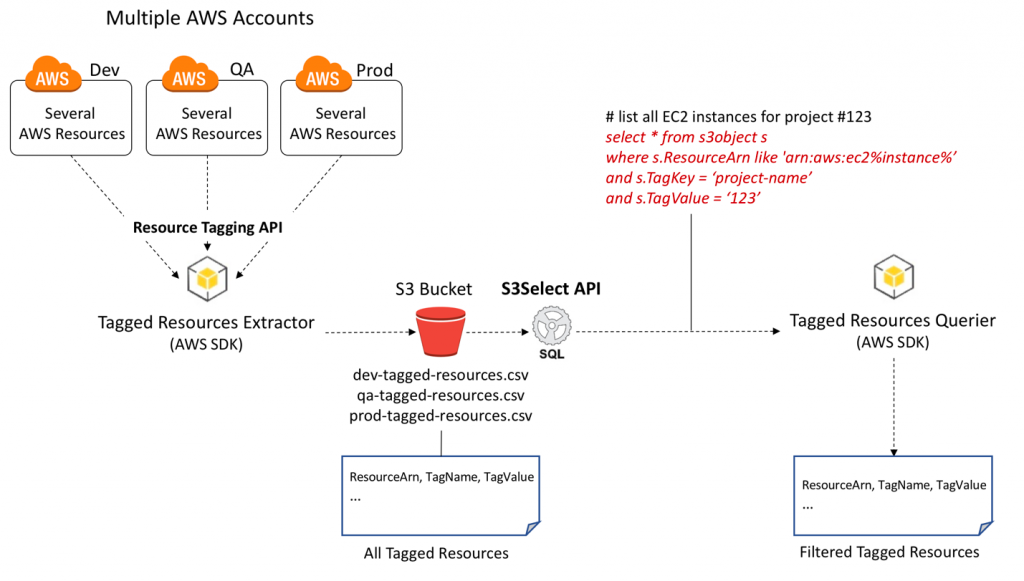
When we are dealing with CSV data on S3, it is usual to want to do some quick checks by running simple queries. We have provided examples of how to query S3 files with AWS Athena and how to work with the AWS Glue. Today, we will show you how you can query a single S3 Object from the console without having to create a database. In another post, we explain how to filter S3 files using the Boto3. Note that AWS S3 Select operates on only a single object and if you want to query multiple S3 files simultaneously using SQL syntax, then you should use AWS Athena.
The S3 Select supports CSV, GZIP, BZIP2, JSON and Parquet files. Let’s see how easily we query an S3 Object.
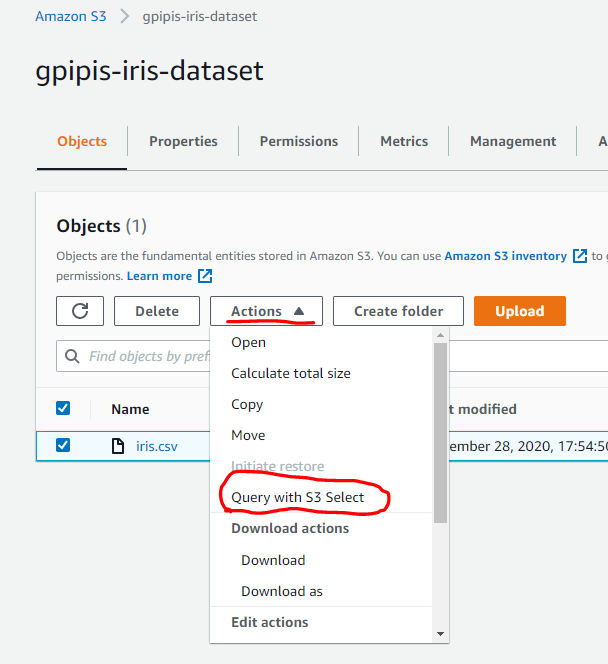
Step 1: Go to your console and search for S3. Once you are on S3 choose the file that you want to query and click on the Actions and then Query with S3 Select
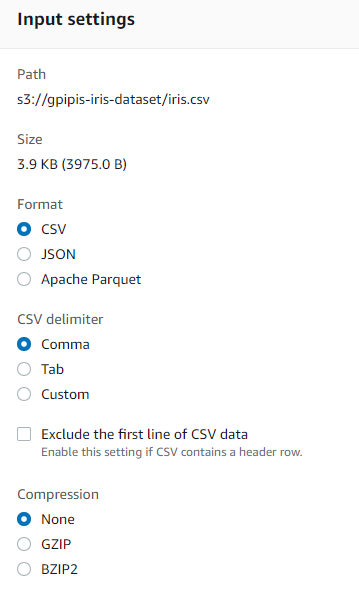
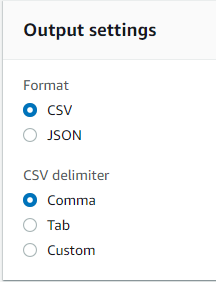
Step 2: Choose the input settings of you file. In my case it is a CSV file and the famous iris dataset! Define also the output setting. I will choose CSV format.
Step 3: Now you are ready to run the SQL statement. Note that there are some templates. the most important thing is that you can choose the columns by name index like _1, _2 etc. . Let’s run a query to get the first 5 rows. We go to the SQL query section and we type:
SELECT * FROM s3object s LIMIT 5
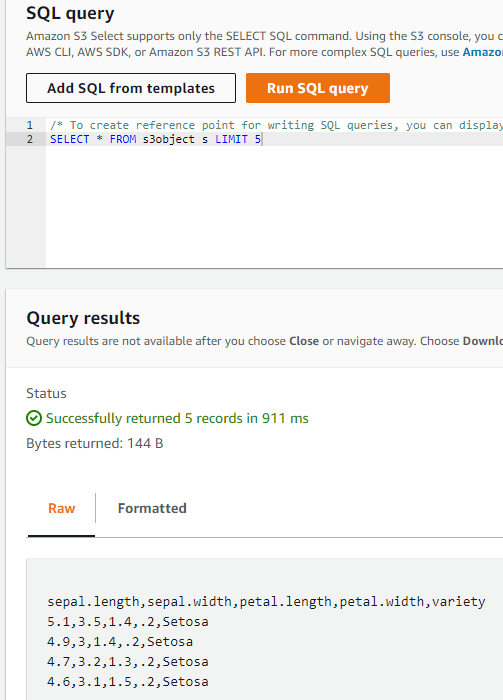
Let’s say that we want to get all the results where the 5th column is Setosa:
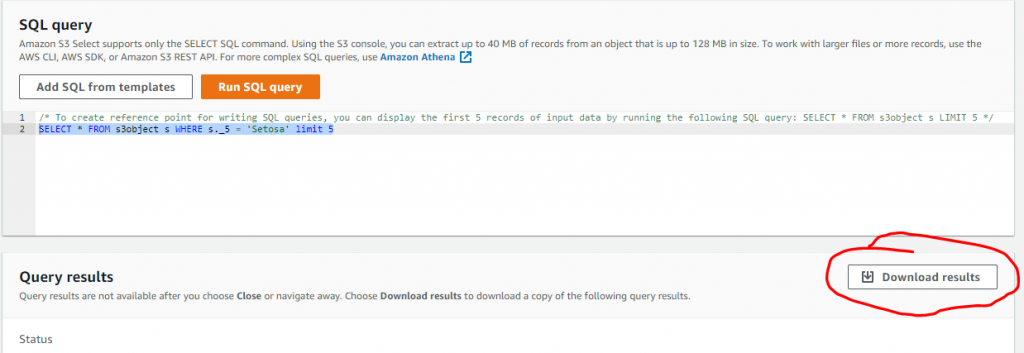
SELECT * FROM s3object s WHERE s._5 = 'Setosa'

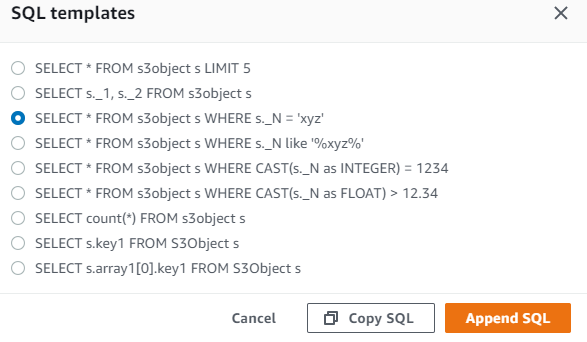
The SQL statements should be at the same line and it supports only the SELECT SQL command. Using the S3 console, you can extract up to 40 MB of records from an object that is up to 128 MB in size. To work with larger files or more records, use the AWS CLI, AWS SDK, or Amazon S3 REST API. For more complex SQL queries, use Amazon Athena. Below we represent a template of the SELECT SQL commands that you can use:
Finally, keep in mind that we are able to download the results in the desired format (JSON, CSV) as defined above in the output settings
S3 Select with Boto3
We have already provided examples of how to apply S3 Select using Boto3.
More Data Science Hacks?
You can follow us on Medium for more Data Science Hacks


