

In the previous posts, we have provided examples of how to interact with AWS using Boto3, how to interact with S3 using AWS CLI, how to work with GLUE and how to run SQL on S3 files with AWS Athena.
Did you know that we can do all these things that we mentioned above using the AWS Data Wrangler? Let’s provide some walk-through examples.
AWS Data Wrangler
AWS Data Wrangler is an AWS Professional Service open-source python initiative that extends the power of Pandas library to AWS connecting DataFrames and AWS data-related services. You can easily install the awswrangler package with the pip command:
pip install awswrangler
In the case that you prefer a conda installation:
conda install -c conda-forge awswrangler
How to Get Data From S3 as Pandas Data Frames
First, we assume that you have already set the AWS credentials in your local machine. In case that you have multiple profiles, you need to work with Boto3 and more particularly with Boto3.Session() like:
import awswrangler as wr import boto3 my_session = boto3.Session(region_name="us-east-2")
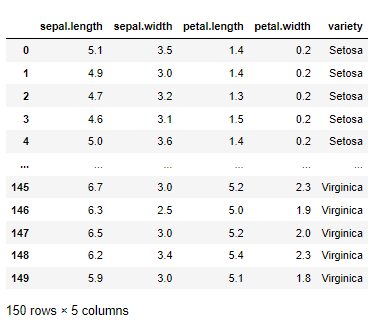
Let’s see how we can get data from S3 to Python as Pandas Data Frames. I have an S3 bucket that contains the iris.csv data.

By running the following command, I will be able to get the data as a pandas data frame:
import awswrangler as wr df = wr.s3.read_csv(path="s3://gpipis-iris-dataset/iris.csv") df
Note that you can pass kwargs pandas arguments. For example:
wr.s3.read_csv(path="s3://gpipis-iris-dataset/iris.csv",
header=None,
sep=',',
skiprows=1,
decimal=',',
na_values=['--'])

How to Write Data to S3
I have created an empty S3 bucket call gpipis_wrangler-example where I will store some data there.
import awswrangler as wr
import pandas as pd
df1 = pd.DataFrame({
"id": [1, 2],
"name": ["foo", "boo"]
})
df2 = pd.DataFrame({
"id": [3],
"name": ["bar"]
})
bucket = 'gpipis-wrangler-example'
path1 = f"s3://{bucket}/file1.csv"
path2 = f"s3://{bucket}/file2.csv"
wr.s3.to_csv(df1, path1, index=False)
wr.s3.to_csv(df2, path2, index=False)
As we can see, both file1.csv and file2.csv have been written to S3.

In order to make sure that we have uploaded correctly the data, let’s download them from S3.
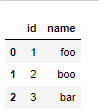
wr.s3.read_csv([path1])

We can read multiple CSV files as follows:
wr.s3.read_csv([path1, path2])

You can either read the data by prefix.
wr.s3.read_csv(f"s3://{bucket}/")
How to Create AWS Glue Catalog database
The data catalog features of AWS Glue and the inbuilt integration to Amazon S3 simplify the process of identifying data and deriving the schema definition out of the discovered data. Using AWS Glue crawlers within your data catalog, you can traverse your data stored in Amazon S3 and build out the metadata tables that are defined in your data catalog. Let’s create a new database called “my_wrangler_db“
wr.catalog.create_database(
name='my_wrangler_db',
exist_ok=True
)
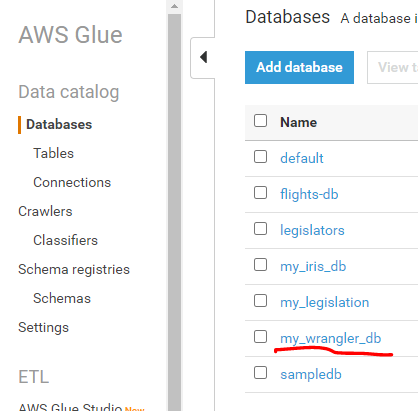
If I go to the AWS Glue, under the Data Catalog and in Databases, I will see the my_wrangler_db.
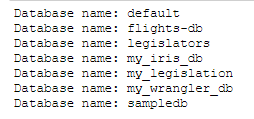
I could get all the databases programmatically using wrangler as follows:
dbs = wr.catalog.get_databases()
for db in dbs:
print("Database name: " + db['Name'])
How to Register Data with AWS Glue Catalog
Let’s see how we can register the data.
wr.catalog.create_csv_table(
database='my_wrangler_db',
path='s3://{}/'.format(bucket),
table="foo",
columns_types={
'id': 'int',
'name': 'string'
},
mode='overwrite',
skip_header_line_count=1,
sep=','
)
If you go to AWS Glue, under the “my_wrangler_db” database there is the foo table.

How to Review that Table Shape
We can get the metadata information of the “foo” table as follows:
table = wr.catalog.table(database='my_wrangler_db',
table='foo')
table

Run Query in AWS Athena
We will see how we can query the data in Athena from our database. Note, that in the case where you do not have a bucket for the Athena, you need to create one as follows:
# S3 bucket name wr.athena.create_athena_bucket()
Now, we are ready to query our database. The query will be the “select * from foo”.
my_query_results = wr.athena.read_sql_query(
sql="""select * from foo""",
database='my_wrangler_db'
)
print(my_query_results)

As we can see, the query returned the expected results. Note that our bucket contains two csv files, however, the catalog was able to merge both of them without adding an extra row for the column name of the second file.
The Takeaway
AWS Wrangler enables us to interact efficiently with the AWS Ecosystem. It is very user-friendly and we can automate many ETL processes.


