

This tutorial is a gentle introduction to tweepy library. We will show you how to get Tweets using Python that you can use later for many other tasks, such as sentiment analysis, trading, and so on.
Install the tweepy Library
There are many Python libraries that act as a Python layer of the Twitter API, but for this tutorial, we will work with the tweepy library. We can install it as follows:
pip install tweepy
Or
conda install -c conda-forge tweepy
Get Access to the Developer Platform of Twitter
You will need to have a Twitter account and sign up for the Developer Portal. Then you will need to fill in some forms explaining the purpose of your application and how you are planning to use the Twitter API. Once you submit the application, you will receive an answer within 10 days. Note that if they reject your application, they do not explain to you the reason and you cannot re-submit a new application! Let’s hope that they will approve your application 🙂
Get the Access and Customer Keys
Once you sign in to the developer portal, you can either create a new app or a standalone app.
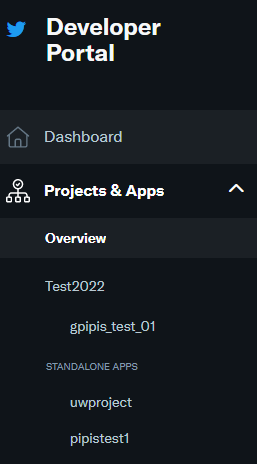
You can click on the Project & Apps and create a new app or standalone app.


Once you create your App, you can click on the “key” button in order to get your credentials. You will find the consumer and the API access tokens and secrets.
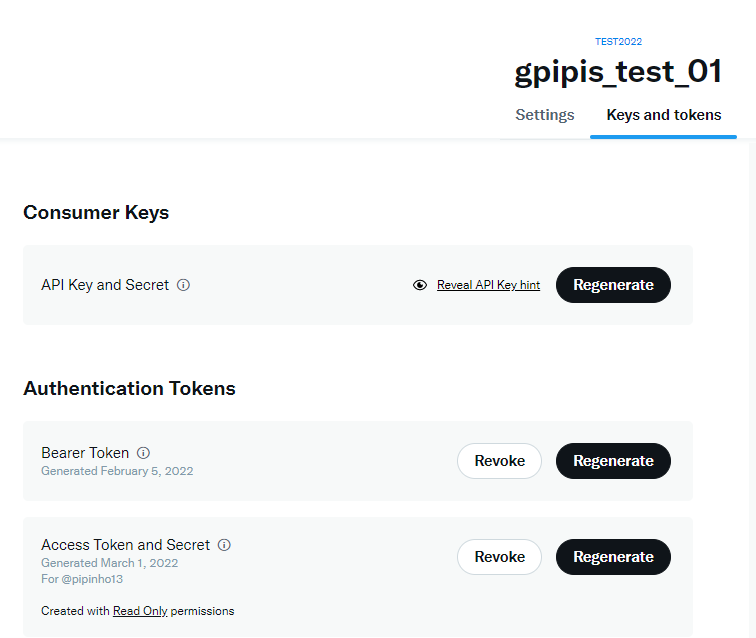
Once you generate the keys, you have to store them because you will not be able to retrieve them again. Of course, you can re-generate new ones.
Get Started with tweepy
Now we are ready to start working with tweepy. I encourage you to store the credentials in a configuration file, as we have explained in a previous post.
import tweepy # your credentials consumer_key = 'xxx' consumer_secret = 'xxx' access_token = 'xxx' access_token_secret = 'xxx' # create the API object auth = tweepy.OAuth1UserHandler( consumer_key, consumer_secret, access_token, access_token_secret ) # Setting wait_on_rate_limit to True when initializing API will initialize an # instance, called api here, that will automatically wait, using time.sleep, # for the appropriate amount of time when a rate limit is encountered api = tweepy.API(auth, wait_on_rate_limit=True)
Get Twitter Data based on Keyword
Let’s say that we want to get all the tweets that contain the hashtag #BTC
# This will search for Tweets with the query "Twitter", returning up to the
# maximum of 100 Tweets per request to the Twitter API
# Once the rate limit is reached, it will automatically wait / sleep before
# continuing
for tweet in tweepy.Cursor(api.search_tweets, q="#BTC", count=100, tweet_mode='extended', until = '2022-03-01').items():
text = tweet._json["full_text"]
print(text)
print('\n\n')
And we get:
RT @Shido_samuraii: در حال حاضر بهترین انجمن مارکتینگ در فضای رمزنگاری هستیم.
♦️#RBXSamurai♦️
⚔️⚔️⚔️⚔️⚔️⚔️
🌐https://t.co/spTgOEOmdo
#RBXS…
RT @crypt_engineer: #Ukriane, ülkeye kripto para bağışında bulunan adreslere #Airdrop ile #token verileceğini duyurdu.
#BTC #ETH #Binance #…
RT @erdemmbozoglu: #HarmonyOne
⚠️0.14 centte söyledim.
⚠️0.125 centte tekrar söyledim.
⚠️Projenin geleceğini, detayını youtube videosu çekt…
RT @foxbit: ☀️Bom dia!
#BTC R$ 225.534,35 (+0,42%)📈
$ETH R$ 15.386,44 (+0,03%)📈
$USDT R$ 5,11 (+0,17%)📈
$SOL R$ 552,26 (+14,02%)📈
$ADA R$…
Are you ready to buy #btc and $alts or waiting for more pull back ?
Which coins will you buy?
🚨🚨🚨are you waiting for me to tell you when to buy lol ?
I am trying to help you buy at the bottom to reduce your risk.
It’s all about being patient. https://t.co/8S0GuM299R
RT @Phemex_official: Spread the love 💖 with Phemex!
Celebrate this lovely Valentine's Day - collect 1 BTC in trial funds and keep your ear…
https://t.co/O7l7EcV8UR #Orijin #Polygon #IDO #BSC #Eth #BTC #Airdrop #DeFi #Launchpad https://t.co/6v9tmXRSph
RT @goatcoiners: $GOAT Town Reveal 🚨
We are building what will become the #Metaverse for legends. You can join the journey now that it’s s…
Instead of a @TodayatEmbr tomorrow, there will be an #Embr Twitter spaces hosted. 17 march will be the next #TaE!
Tune in at 4 PM ET/9 PM UTC @joinembr to chat about #embr and other #crypto or #DeFi news or topics.
See you tomorrow 🔥
#BNB #btc #cedefi #doxxed #amazingplans
2022-03-02 @Trailblazers at @Suns
picks: FG #RipCity +10.5
#NBA #soccer #machinelearning #btc https://t.co/JeLBJ96teJ
Notice that the “tweets” we get from the cursor are “Status” objects.
type(tweet)
tweepy.models.StatusAnd it contains a lot of information.
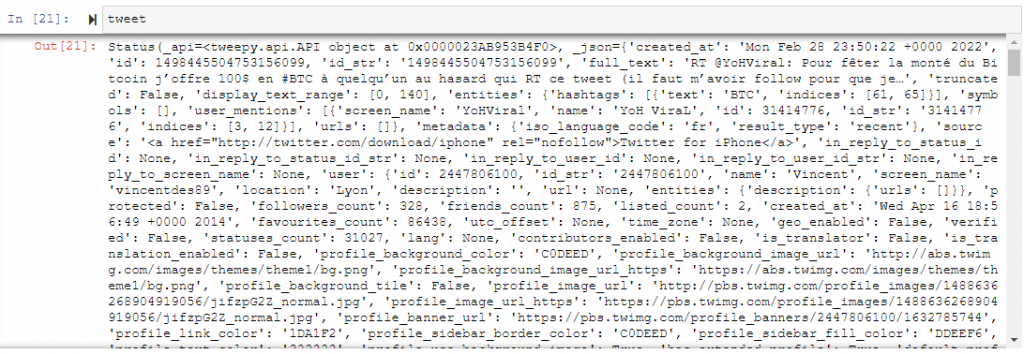
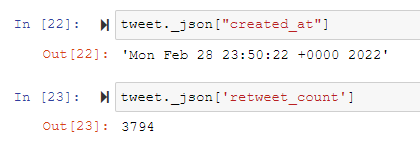
We can extract other information such as the number of retweets, the creation date and so on.
tweet._json["created_at"] tweet._json['retweet_count'] tweet._json['favorite_count']
Get Tweets from a User Timeline
We can get the tweets of a specific user timeline. Let’s get the tweets of the Predictive Hacks Twitter account. We will get the latest 10.
statuses = api.user_timeline(screen_name='predictivehacks', count=10, tweet_mode="extended")
for status in statuses:
print(status._json['full_text'])
Docker Tutorials from FREE 👇 - https://t.co/kIkJoa7vsc
How to work with VS Code and Virtual Environments in Python
#vscode #pythonprogramming #Python
https://t.co/dTElIkzmBO
How to Save and Load Scikit ML Models in Python
#Python #MachineLearning #sklean #DataScience #tutorial
https://t.co/6qiCr6r4C7
Read my latest: “FinTech Tutorials from Predictive[Hacks]” https://t.co/BonjBfl0xc
AWS Tutorials from FREE 👇 - https://t.co/HQRPxi28sl
Read my latest: “Weekly newsletter of Predictive[Hacks] https://t.co/SFliNddi9c
Google, rivals unite on smart tech https://t.co/Zxgu8W23Bn
Weekly newsletter of Predictive[Hacks] - Issue #1 by @predictivehacks https://t.co/5gSZMQapyj via @revue
I just published in @gitconnected Web Article NLP Analysis in Python https://t.co/Jvxgpe9QQ9
#NLP #pythonlearning #DataScience
I just published in @startitup_ A Tutorial About Market Basket Analysis in Python https://t.co/eoQKGDkoYl
#Python #pythonlearning #dataScientist #DataScienceBelow, you can find the parameters of the user_timeline. Notice that it returns
Parameters
- user_id – Specifies the ID of the user. Helpful for disambiguating when a valid user ID is also a valid screen name.
- screen_name – Specifies the screen name of the user. Helpful for disambiguating when a valid screen name is also a user ID.
- since_id – Returns only statuses with an ID greater than (that is, more recent than) the specified ID.
- count – The number of results to try and retrieve per page.
- max_id – Returns only statuses with an ID less than (that is, older than) or equal to the specified ID.
- trim_user – A boolean indicating if user IDs should be provided, instead of complete user objects. Defaults to False.
- exclude_replies – This parameter will prevent replies from appearing in the returned timeline. Using
exclude_replieswith thecountparameter will mean you will receive up-to count Tweets — this is because thecountparameter retrieves that many Tweets before filtering out retweets and replies. - include_rts – When set to
false, the timeline will strip any native retweets (though they will still count toward both the maximal length of the timeline and the slice selected by the count parameter). Note: If you’re using the trim_user parameter in conjunction with include_rts, the retweets will still contain a full user object.
We can also get the tweets of a user using the cursor as follows:
for tweet in tweepy.Cursor(api.user_timeline, screen_name='predictivehacks', tweet_mode="extended").items():
text = tweet._json["full_text"]
print(text)
print('\n\n')
And we get:
Docker Tutorials from FREE 👇 - https://t.co/kIkJoa7vsc
How to work with VS Code and Virtual Environments in Python
#vscode #pythonprogramming #Python
https://t.co/dTElIkzmBO
How to Save and Load Scikit ML Models in Python
#Python #MachineLearning #sklean #DataScience #tutorial
https://t.co/6qiCr6r4C7
Read my latest: “FinTech Tutorials from Predictive[Hacks]” https://t.co/BonjBfl0xc
AWS Tutorials from FREE 👇 - https://t.co/HQRPxi28sl
Read my latest: “Weekly newsletter of Predictive[Hacks] https://t.co/SFliNddi9c
Google, rivals unite on smart tech https://t.co/Zxgu8W23Bn
Weekly newsletter of Predictive[Hacks] - Issue #1 by @predictivehacks https://t.co/5gSZMQapyj via @revue
I just published in @gitconnected Web Article NLP Analysis in Python https://t.co/Jvxgpe9QQ9
#NLP #pythonlearning #DataScience
I just published in @startitup_ A Tutorial About Market Basket Analysis in Python https://t.co/eoQKGDkoYl
#Python #pythonlearning #dataScientist #DataScience
Rename and Relevel Factors in R
#RStats #rstudio #DataScience
https://t.co/mGS09l2Suu
How To Backtest your Crypto Trading Strategies in R
https://t.co/QKzKhVVZ8K
#cryptocurrency #trading #backtesting #RStats #rstudio #fintechs #DataScience
Moving Average in PostgreSQL
#SQL #Postgres #Tips #DataScience #dataengineering
https://t.co/UnN54orQ63 https://t.co/w1dxqgwg0K
Get the Trends
We can also get the trends by location. First, we will need to find the WOEID of the country that we want to get the trends. Let’s say that we want to get the trends of Greece. The api.available_trends() returns a list of dictionaries such as:
This means, that in order to retrieve the WOEID of Greece we need to extract it from the output. For example:
output = api.available_trends()
for el in output:
if el['country'] == 'Greece':
print(el)
And we get:
{'name': 'Athens', 'placeType': {'code': 7, 'name': 'Town'}, 'url': 'http://where.yahooapis.com/v1/place/946738', 'parentid': 23424833, 'country': 'Greece', 'woeid': 946738, 'countryCode': 'GR'}
{'name': 'Thessaloniki', 'placeType': {'code': 7, 'name': 'Town'}, 'url': 'http://where.yahooapis.com/v1/place/963291', 'parentid': 23424833, 'country': 'Greece', 'woeid': 963291, 'countryCode': 'GR'}
{'name': 'Greece', 'placeType': {'code': 12, 'name': 'Country'}, 'url': 'http://where.yahooapis.com/v1/place/23424833', 'parentid': 1, 'country': 'Greece', 'woeid': 23424833, 'countryCode': 'GR'}We can see that the WOEID is the 23424833. Notice that we can get the WOEID of specific cities too. So we can get the trends by running the command:
greece_trends = api.get_place_trends(23424833)
for trend in greece_trends[0]['trends']:
print(trend['name'])
And we get:
#staralithies
#γυναικοκτονια
#shoppingstar
#Πολεμος_στην_Ουκρανια
#AEKPAOK
Συλλυπητηρια
Ζηνα
πολυχρονος
μαμαλακης
hobi
Μερα 18
καλοταξιδο
Κουστουριτσα
μαθιο
καλημερα μασια
ο κοντιζας
ευαγγελατο
στελλαςFinal Thoughts
The tweepy library is very powerful but the documentation is not so good and it lacks hands-on examples. The Data Scientist can monetize the Twitter API by running several types of analysis with applications in many fields such as finance, politics, health, marketing and so on.


