

AWK appeared back in 1977 and is a programming language designed for text processing that is used mainly for data processing. In the Data Science and Data Engineering world, the AWK language is a great tool for data munging. In this post, we will try to unlock the power of AWK by using examples.
For demonstration purposes, we will work with the following simple files and you can follow along!
eg.csv
ID,Name,Dept,Gender 1,George,DS,M 2,Billy,DS,M 3,Nick,IT,M 4,George,IT,M 5,Nikki,HR,F 6,Claudia,HR,F 7,Maria,Sales,F 8,Jimmy,Sales,M 9,Jane,Marketing,F 10,George,DS,M
Records and Fields in AWK
AWK works with text files. The default field separator is the white space, and the default record separator is the new line feed \n. However, we are able to define the records and the fields. Before we provide some concrete examples, let’s focus on the most important built-in variables:
- NR: It keeps the current number of the input records
- NF: It keeps the number of fields of the current record
- FS: The input field separator, where the default is the white space
- RS: The input record separator, where the default is the new line feed
- OFS: The output field separator
- ORS: The output record separator
You will have a clear view of the built-in variables with the following examples.
How to Return the First Lines of the File
What is the first thing that we use to do when we get a file? Simply, it is to run the “head” command in order to get an idea of the data. Let’s see how we can return the first 5 lines with AWK. Note that we use the NR option (NR<=5).
awk 'NR<=5 {print}' eg.csv

Let’s say what we want to return the 6th to 10th row, we can easily do it as follows:
awk 'NR<=10 && NR>=6 {print}' eg.csv
Finally, let’s say that we want to return the 6th to 10th row plus the header, which is the first row.
awk '(NR<=10 && NR>=6)||(NR==1) {print}' eg.csv
How to Filter Rows
We can easily filter lines based on some conditions. In the next example, we will return all the rows that contain the string “Sales“.
awk '/Sales/ {print}' eg.csv

Similarly, we can return all the rows that contain the “HR” or the “Sales” string.
awk '/HR|Sales/ {print}' eg.csv

We can use other regular expressions. For example, we are looking for rows that contain the “Geo” string followed by something and then followed by “IT“:
awk '/Geo.*IT/ {print}' eg.csv

Moreover, we can return the rows that DO NOT contain the required string. For example, we want to return are the rows that do not contain HR or Sales.
awk '!/HR|Sales/ {print}' eg.csv

How to Select Columns
The first thing that we can learn is how to select columns in AWK. But before we go there, let’s see how we can print the file. The command is:
awk '{print}' eg.csv
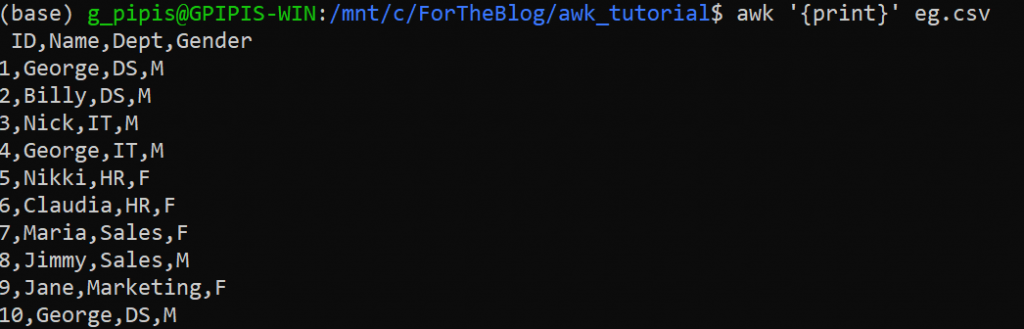
Note, that we can print all the rows by running:
awk '{print $0}' eg.csv
If we want to return specific columns, we can use the $ symbol and the number of the required column. Note that the default delimiter is the “white space”, but we can change it by using the “F” option or the “FS” variable. Let’s say that we want to return the 2nd and the 4th column.
awk -F ',' '{print $2, $4}' eg.csv
Or
awk '{print $2, $4}' FS=',' eg.csv
Or
awk 'BEGIN{FS=","} {print $2, $4}' eg.csv
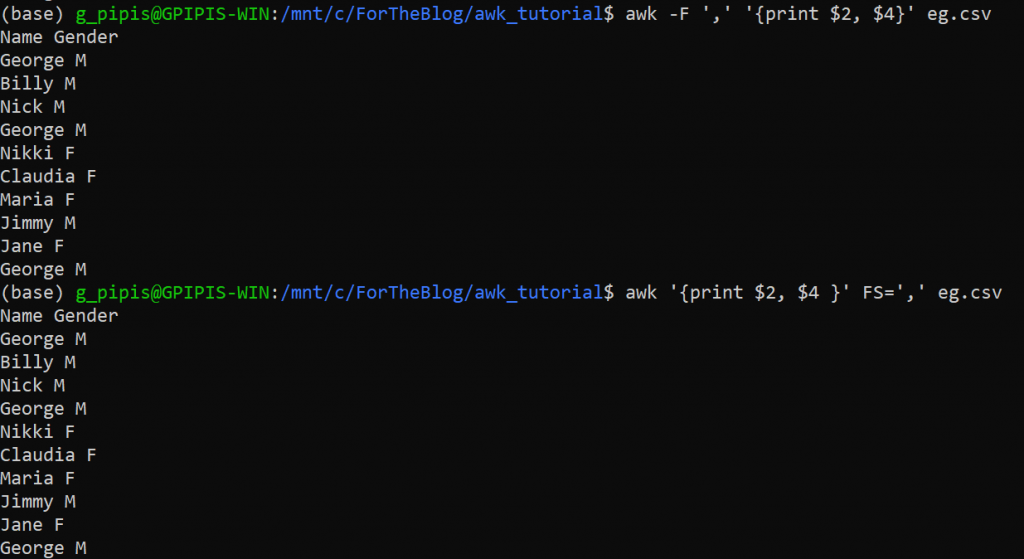
As you can see, we successfully returned the required columns.
Tips: The delimiter is not necessary to be enclosed in quotation marks unless it is a regular expression. Finally, if the separator is a tab, you can specify it with “\t“.
How to Filter Rows based on Columns Conditions
We have already seen how to filter rows by searching for a string within a line and how to select columns. Now, we can see how to filter rows based on some conditions in particular columns.
For example, let’s say that we want all the rows where the department is “DS“.
awk -F"," '$3=="DS" {print $0}' eg.csv

Notice that the Department is the third column.
Let’s say that we want to return all the rows where the ID is greater than 5.
awk -F"," '$1>5{print $0}' eg.csv

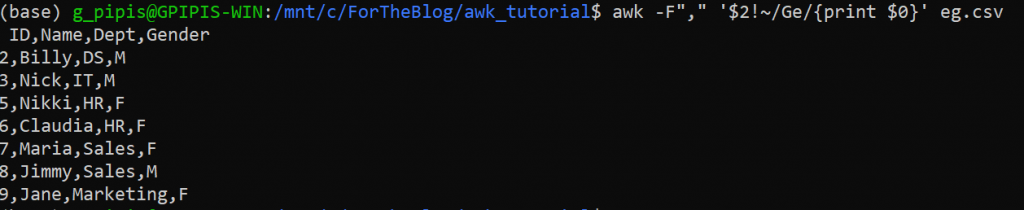
We can also get the rows where a specific column contains a substring. In this case, we need to use the “~” symbol plus the slashes “/” for the regular expression. For example, let’s get all the rows where there is the substring “Ge” in the second column.
awk -F"," '$2~/Ge/{print $0}' eg.csv

If we wanted the invert expression, meaning the lines where the column name DOESN’T contain the substring “Ge” we could have run:
awk -F"," '$2!~/Ge/{print $0}' eg.csv
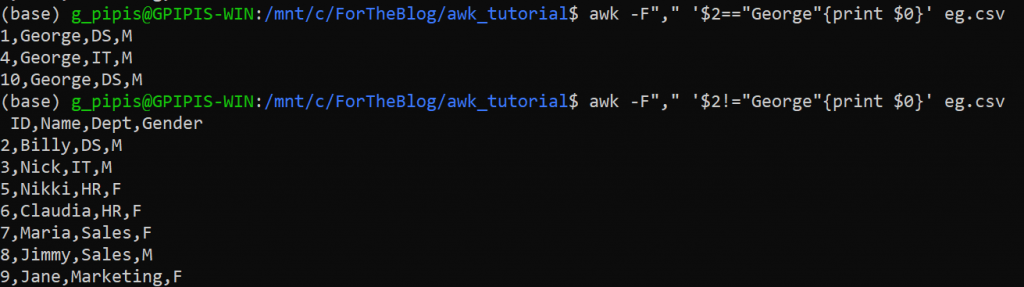
Finally, if we want the exact match, like getting all the rows where the name is George
awk -F"," '$2=="George"{print $0}' eg.csv
and for the invert expression is:
awk -F"," '$2!="George"{print $0}' eg.csv
How to Change the Delimiter
There are at least two different ways to change the file delimiter of the file. Let’s assume that I want to convert the CSV file to TSV.
awk -F "," '{print $1 "\t" $2 "\t" $3 "\t" $4}' eg.csv
Or
awk 'BEGIN{FS=",";OFS="\t"} {print $1, $2, $3, $4}' eg.csv
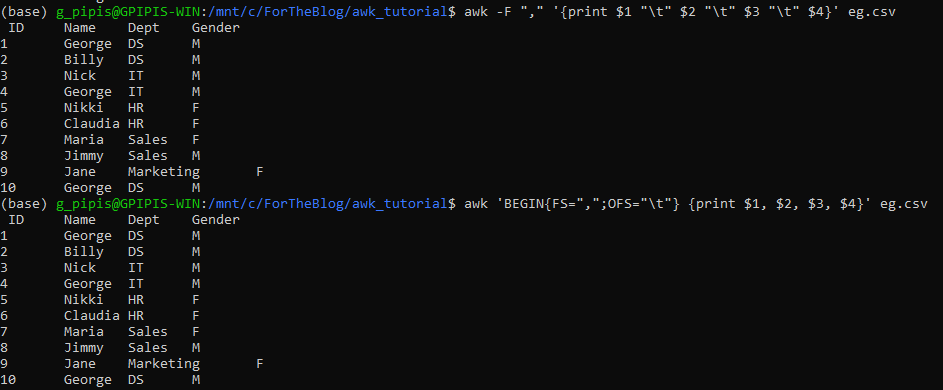
We can also save the TSV file as follows:
awk 'BEGIN{FS=",";OFS="\t"} {print $1, $2, $3, $4}' eg.csv > eg.tsv
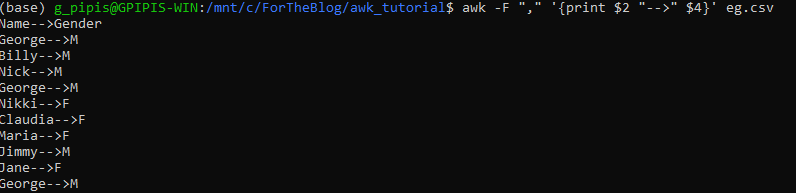
How to Concatenate Fields
We can easily concatenate fields with the print statements. Let’s say that we want to add the --> between Name and Gender.
awk -F "," '{print $2 "-->" $4}' eg.csv
How to Print the Number of Fields by Record
As we have mentioned earlier, we can specify the field separator. With AWK we can get the number of fields by row. For example:
awk -F "," '{print NF, $0}' eg.csv
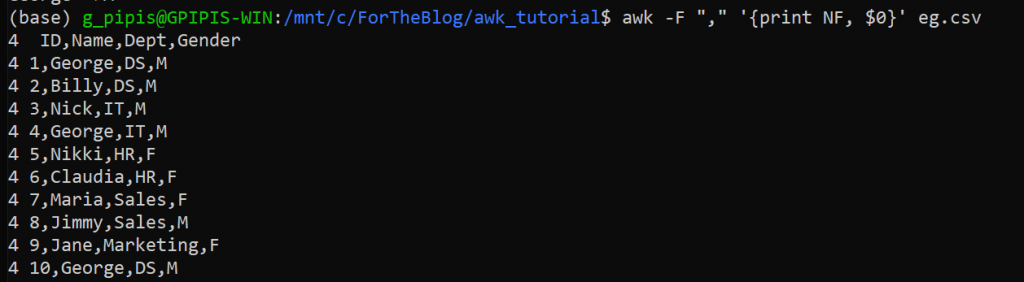
As we can see, we got 4 for each record as expected, since we have four fields.
How to Count the Lines of a File
Another very common task is to get the number of lines of a file. In Unix, we can get it as follows:
cat eg.csv | wc -l
Using AWK we can run the equivalent command as follows:
awk 'END {print NR}' eg.csv
Not surprisingly, in both cases, we got 11.

How to Get the Sum of a Column
Let’s say that we want to get the sum of the ID column. We can easily do it as follows:
awk -F "," '{mysum+= $1} END {print mysum}' eg.csv

As we can see we got 55 (=1+2+3+4+5+6+7+8+9+10). In the above command, we defined a variable called “mysum” where for every row we add the corresponding record of the first column ($1).
How to Concatenate Multiple CSV Files
Assume that we have many CSV files of the same format and we want to merge them into one file, but we want to keep the header of the first file only! We can do it with AWK as follows:
awk '(NR == 1) || (FNR > 1)' my_file_*.csv > merged.csv
FNR refers to the number of the processed record in a single file and NR refers to all files, so we keep the first line which is the header and we ignore the first lines of each file.
Finally, if you want to remove the headers from all files:
awk 'FNR > 1' my_file_*.csv > merged.csv
Closing Words
I strongly believe that Data Scientists and Data Engineers should have a relatively good background in UNIX to be used mainly for text processing and data pipelines tasks. AWK is a really powerful tool for data cleansing tasks and is a good technical skill to have. The goal of this tutorial was to introduce you to the AWK world. There are many other things that we can do with AWK and if you want to learn more, then the only thing that you need to do is to stay tuned!


