

In retrieval augmented generation (RAG), an LLM retrieves contextual documents from an external dataset as part of its execution, which enables us to ask questions about the context of the documents. These documents can be plain text files, PDFs, URLs and even videos, like YouTube videos.
In this tutorial, we will show you how to upload a YouTube using LangChain.
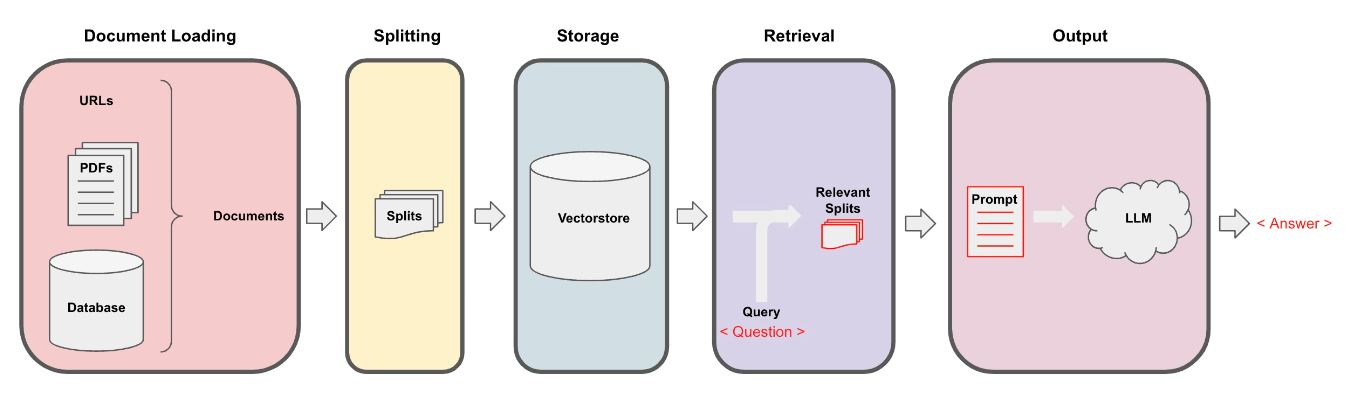
YouTube Video Loading with LangChain
The YouTube loader enables users to extract text from videos. It highlights the importance of this functionality for engaging with favorite videos or lectures. This loader incorporates components such as the YouTube audio loader and the OpenAI Whisper parser, facilitating the conversion of YouTube audio into text. The process involves specifying a URL, a directory for saving audio files, and then combining the YouTube audio loader with the OpenAI Whisper parser to create a generic loader. Upon loading the documents, users can view the transcript of the YouTube video. The text encourages readers to try the transcription with their preferred YouTube videos.
Let’s move on with a concrete example.
Load the Libraries
We assume that you have already installed the LangChain and that you have passed your OpenAI key. You will need to download the following libraries:
%pip install --upgrade --quiet yt_dlp %pip install --upgrade --quiet pydub %pip install --upgrade --quiet librosa
Once you are ready, you can load the required libraries.
import os
import openai
import sys
from langchain.document_loaders.generic import GenericLoader
from langchain.document_loaders.parsers import OpenAIWhisperParser
from langchain.document_loaders.blob_loaders.youtube_audio import YoutubeAudioLoader
sys.path.append('../..')
We will download the Let’s build GPT: from scratch, in code, spelled out YouTube Video by Adrej Karpathy.
# Karpathy's lecture url = "https://youtu.be/kCc8FmEb1nY" # Directory to save audio files save_dir = "~/Downloads/YouTube" loader = GenericLoader(YoutubeAudioLoader(url, save_dir), OpenAIWhisperParser()) docs = loader.load()
Let’s get the first 500 characters
# Returns a list of Documents, which can be easily viewed or parsed docs[0].page_content[0:500]
Output:
"Hello, my name is Andrej and I've been training deep neural networks for a bit more than a decade. And in this lecture I'd like to show you what neural network training looks like under the hood. So in particular we are going to start with a blank Jupyter notebook and by the end of this lecture we will define and train a neural net and you'll get to see everything that goes on under the hood and exactly sort of how that works on an intuitive level. Now specifically what I would like to do is I w"Q&A Retrieval Models
Now, we are in a position to ask questions and get answers. Let’s see how we can do that.
from langchain.chains import RetrievalQA from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.vectorstores import FAISS from langchain_openai import ChatOpenAI, OpenAIEmbeddings
Let’s combine the docs into one string object called text.
# Combine doc combined_docs = [doc.page_content for doc in docs] text = " ".join(combined_docs)
The next step is to split the text into chunks and to build an index.
# Split them text_splitter = RecursiveCharacterTextSplitter(chunk_size=1500, chunk_overlap=150) splits = text_splitter.split_text(text) # Build an index embeddings = OpenAIEmbeddings() vectordb = FAISS.from_texts(splits, embeddings)
Finally, we can build the QA chain.
# Build a QA chain
qa_chain = RetrievalQA.from_chain_type(
llm=ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0),
chain_type="stuff",
retriever=vectordb.as_retriever(),
)
Now, it is time to test it. Let’s ask the following question:
What is the difference between an encoder and decoder?
query = "What is the difference between an encoder and decoder?" qa_chain.run(query)
Output:
‘In the context of transformers, an encoder is a component that reads in a sequence of input tokens and generates a sequence of hidden representations. On the other hand, a decoder is a component that takes in a sequence of hidden representations and generates a sequence of output tokens. The main difference between the two is that the encoder is used to encode the input sequence into a fixed-length representation, while the decoder is used to decode the fixed-length representation into an output sequence. In machine translation, for example, the encoder reads in the source language sentence and generates a fixed-length representation, which is then used by the decoder to generate the target language sentence.’
Amazing, isn’t it? We were able to get a lecture/tutorial from YouTube to make questions related to the content and get the right answers.
Sources: LangChain Documentation


