

When I run quires in SQL (or even HiveQL, Spark SQL and so on), it is quite common to use the syntax of count(case when.. else ... end). Today, I will provide you an example of how you run this type of commands in dplyr.
Let’s start:
library(sqldf)
library(dplyr)
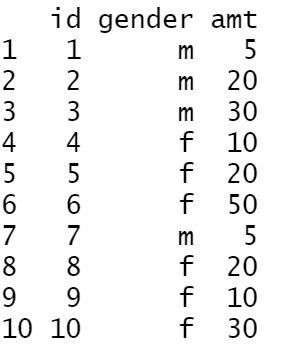
df<-data.frame(id = 1:10,
gender = c("m","m","m","f","f","f","m","f","f","f"),
amt= c(5,20,30,10,20,50,5,20,10,30))
df
Let’s get the count and the sum per gender in different columns in SQL.
sqldf("select count(case when gender='m' then id else null end) as male_cnt,
count(case when gender='f' then id else null end) as female_cnt,
sum(case when gender='m' then amt else 0 end) as male_amt,
sum(case when gender='f' then amt else 0 end) as female_amt
from df")
Output:
male_cnt female_cnt male_amt female_amt
1 4 6 60 140Let’s get the same output in dplyr. We will need to subset the data frame based on one column.
df%>%summarise(male_cnt=length(id[gender=="m"]),
female_cnt=length(id[gender=="f"]),
male_amt=sum(amt[gender=="m"]),
female_amt=sum(amt[gender=="f"])
)
Output:
male_cnt female_cnt male_amt female_amt
1 4 6 60 140


2 thoughts on “Hack: The “count(case when … else … end)” in dplyr”
The awkwardness with the R version mainly comes from requiring the result to be in an awkward form. A more usual way of achieving an equivalent result in a better form would be to use
df %>%
group_by(gender) %>%
summarise(n = n(), amt = sum(amt), .groups = ‘drop’)
The output is in a different format. You can use the tidyR package to reshape the results. However, our goal here was to show the equivalent of “case when” in dplyr