
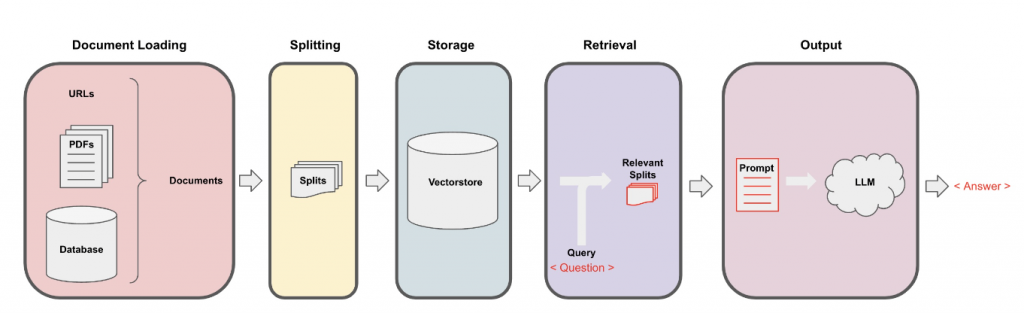
In this tutorial, we will provide a walk-through example of how to use your data and ask questions using LangChain. The steps are the following:

- Load the Document
- Create chunks using a text splitter
- Create embeddings from the chunks
- Store the embeddings in a vector database (Chroma DB in our case)
- Use a retrieval model to get similar documents to your question
- Feed the ChatGPT model with the content of similar documents to get a tailored answer
- Explain who to keep the memory of your conversation to have a chat with your data
Let’s jump into the coding part!
Load the required libraries
from langchain.document_loaders import TextLoader from langchain.text_splitter import CharacterTextSplitter from langchain.embeddings.openai import OpenAIEmbeddings from langchain.vectorstores import Chroma from langchain.chat_models import ChatOpenAI from langchain.chains import RetrievalQA from langchain.prompts import PromptTemplate from langchain.memory import ConversationBufferMemory from langchain.chains import ConversationalRetrievalChain
As a document, we will use a txt file called facts.txt that contains some facts. At this point, we will load the document and we will split it into chunks.
text_splitter = CharacterTextSplitter(
separator = "\n",
chunk_size = 200,
chunk_overlap = 0
)
loader = TextLoader("docs/txt_documents/facts.txt")
docs = loader.load()
splits = text_splitter.split_documents(docs)
The next step is to create the embeddings and store them in a database.
embedding = OpenAIEmbeddings()
persist_directory = 'docs/chroma/'
vectordb = Chroma.from_documents(
documents=splits,
embedding=embedding,
persist_directory=persist_directory
)
# save the database so we can use it later
vectordb.persist()
# check that the database have been created and get the number of documents
print(vectordb._collection.count())
Output:
54
Let’s get some similar documents by running the following questions:
“tell me a fact about ostriches”
For each document, we will return the distance as well. The smaller the number, the more relevant the document is. Keep in mind that in our document, each fact corresponds to one line and as a result, each chunk consists of different facts.
# similarity search
question = "tell me a fact about ostriches"
docs = vectordb.similarity_search_with_score(question,k=3)
for result in docs:
print("\n")
print(result[1])
print(result[0].page_content)
0.3597276056751038 101. Avocado has more protein than any other fruit. 102. Ostriches can run faster than horses. 103. The Golden Poison Dart Frog’s skin has enough toxins to kill 100 people. 0.3783363542359751 1. "Dreamt" is the only English word that ends with the letters "mt." 2. An ostrich's eye is bigger than its brain. 3. Honey is the only natural food that is made without destroying any kind of life. 0.4047550216944485 54. The kangaroo and the emu are featured on the Australian coat of arms because neither animal can move backward, indicating progress.
As you can see, the first two documents contain the word “ostrich” but the 3rd one does not. However, it contains the word “emu” which is a bird similar to “ostrich”. This is an example of how powerful the embeddings are.
Now, we will re-load the vector database, and we will feed the ChatGPT with the similar documents that we got from the retriever, and we will ask to get a tailored answer.
persist_directory = 'docs/chroma/'
# load again the db
vectordb = Chroma(
persist_directory=persist_directory,
embedding_function=embedding
)
# Q&A
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever()
)
result = qa_chain({"query": question})
print(result["result"])
Output:
Ostriches can run faster than horses.
Ostriches can run faster than horses.
With the help of ChatGPT we managed to get a specific answer. Let’s see how we can work with templates.
# Build prompt
template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
# Run chain
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
print(result["result"])
Output:
'Ostriches can run faster than horses.'
Finally, let’s see how we can chat with our data by keeping in memory the chat history.
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
qa = ConversationalRetrievalChain.from_llm(
llm,
retriever=vectordb.as_retriever(),
memory=memory
)
result = qa({"question": question})
print(result['answer'])
Output:
'Ostriches can run faster than horses.'
No, we will ask, “what is the maximum speed that they can reach?” and the model will understand that we are referring to ostriches.
question = "what is the maximum speed that they can reach?"
result = qa({"question": question})
print(result['answer'])
Output:
'Ostriches can reach speeds of up to 60 miles per hour.'
Sources
[1]: Deeplearning.AI


