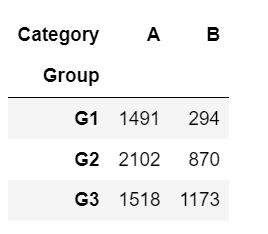
In SQL it is common to write statements using the following syntax:
select mygroup, sum(case when category='A' then Value else 0 end) as CatgoryA, sum(case when category='B' then Value else 0 end) as CatgoryB from mytable group by mygroup
The above case is not so common in Pandas since we can get the same output by using pivot tables. But let’s see how we can write the above statement in Python using Pandas.
import numpy as np
import pandas as pd
np.random.seed(5)
Category = np.random.choice(['A','B'], 100, p=[0.7,0.3])
Group = np.random.choice(['G1','G2', 'G3'], 100)
Value = np.random.randint(low=50, high=100, size=100)
df = pd.DataFrame({'Group':Group, 'Category':Category, 'Value':Value})
df
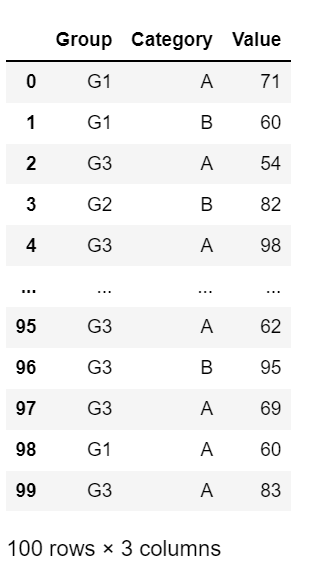
We have generated a data frame and we are ready to move on.
df.groupby('Group', as_index=False).apply(lambda x: pd.Series({'CatA':x.loc[x.Category=='A']['Value'].sum(),
'CatB':x.loc[x.Category=='B']['Value'].sum()}))
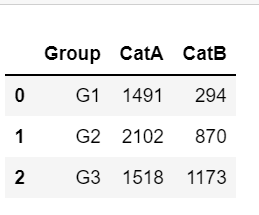
As we can see we get the same results with the pivot table.
df.pivot_table(values='Value', index='Group', columns='Category', aggfunc=np.sum)