For recommender systems and collaborative filters it is a good strategy to centralize your data around 0 by subtracting the mean value and then filling the NAs with 0. Depending on your dataset and what you want to do, the centralization can be by row or by column.
Centralize a pandas data frame by row
In this case, we want to subtract the row mean from each element in a row. Let’s see how we can do it with on line of code.
import pandas as pd
import numpy as np
df = pd.DataFrame({'ColA': [1, 2, 3], 'ColB': [4, 10, 12], 'ColC': [10, np.nan, 7]})
df

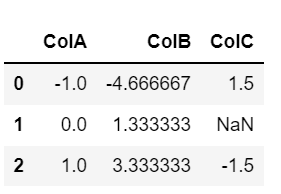
Centralize the data frame:
df_centralized = df.sub(df.mean(axis=1), axis=0) df_centralized
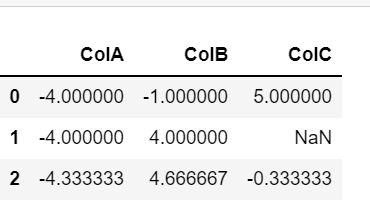
Centralize a pandas data frame by column
Similarly, we can centralize it by subtracting the column mean for each element in a row.
df_centralized = df.sub(df.mean(axis=0), axis=1) df_centralized