
In this post, we will provide you an example of how you can write a regular expression (regex) that searches for the exact match of the input. We will work with Python and Pandas. Let’s provide a dummy Pandas data frame with documents.
import re
import pandas as pd
df = pd.DataFrame({'ID':[1,2,3,4,5],
'Document':['This t-shirt costs 30$',
'I am 30 years old',
'There is a discount of $ 30',
'Now you can get it with 30% off',
'I am 30+ :)']})
df

When we are dealing with symbols like $, %, + etc at the start of or at the end of the input, the regular expression with the word boundaries does not work. Below, we represent a “hack” of how you can return the documents that contain the exact input keyword.
Examples
The regular expression that returns the exact match is the following:
(?<!\w)input(?!\w)
where input is the user’s input. Let’s try to explain the regular expression.
(?<!...) Matches if the current position in the string is not preceded by a match for .... This is called a negative lookbehind assertion. Similar to positive lookbehind assertions, the contained pattern must only match strings of some fixed length. Patterns which start with negative lookbehind assertions may match at the beginning of the string being searched.
(?!...) Matches if ... doesn’t match next. This is a negative lookahead assertion. For example, Isaac (?!Asimov) will match 'Isaac ' only if it’s not followed by 'Asimov'.
\w Matches Unicode word characters; this includes most characters that can be part of a word in any language, as well as numbers and the underscore. If the ASCII flag is used, only [a-zA-Z0-9_] is matched.
Return the documents which contain the “30%”
Notice that it is important to sanitize the input by adding the escape characters when this is necessary. For example:
keyword = "30%"
keyword = re.escape(keyword)
df.loc[df.Document.str.contains(rf"(?<!\w){keyword}(?!\w)", case=False, regex=True)]
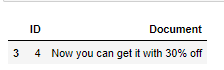
Return the documents which contain the “30+”
keyword = "30+"
keyword = re.escape(keyword)
df.loc[df.Document.str.contains(rf"(?<!\w){keyword}(?!\w)", case=False, regex=True)]

Return the documents which contain the “$ 30”
keyword = "$ 30"
keyword = re.escape(keyword)
df.loc[df.Document.str.contains(rf"(?<!\w){keyword}(?!\w)", case=False, regex=True)]



