

Sed (stream editor) is a very powerful tool for parsing and transforming text that was developed back in 1973 at Bell Labs. Usually, you can find sed pre-installed in any UNIX variant, but it is possible that you will need to install it.
In this tutorial, we will show you the basic use of sed commands with examples. For the examples, we will work with the following two files.
eg.csv
ID,Name,Dept,Gender 1,George,DS,M 2,Billy,DS,M 3,Nick,IT,M 4,George,IT,M 5,Nikki,HR,F 6,Claudia,HR,F 7,Maria,Sales,F 8,Jimmy,Sales,M 9,Jane,Marketing,F 10,George,DS,M
myfile.txt
This is the first line bla bla bla This is the second line bla bla bla This is the third line bla bla bla some other text is here This is Predictive Hacks a Data Science blog and this is the last line of this non sense text
Before we start with the examples, let’s check if the sed is installed in our system.
sed --version
Since we have installed sed, we are good to go!
How to Replace Values by Line
The most common command of sed is the 's/pattern/value/' where it searches for a string “pattern” and it replaces it with the required value. Note that the “s” comes from “substitute“. Let’s dive into an example, where we would like to change the “bla” with “BLA” from the myfile.txt.
sed 's/bla/BLA/' myfile.txt
And we get:
This is the first line BLA bla bla This is the second line BLA bla bla This is the third line BLA bla bla some other text is here This is Predictive Hacks a Data Science blog

Note: As we can see, it replaced only the first occurrence of “bla” with “BLA” per each line.
If we want to replace every occurrence, then we should add the “g” in the expression (‘s/pattern/value/g’). The “g” comes from “global”.
sed 's/bla/BLA/g' myfile.txt
And we get:
This is the first line BLA BLA BLA This is the second line BLA BLA BLA This is the third line BLA BLA BLA some other text is here This is Predictive Hacks a Data Science blog

As we can see, we replaced every occurrence of “bla” with “BLA”.
How to Replace the n-th Occurrence with a Value
Let’s say that we want to replace the third occurrence of the word “bla” with “BLA” within each line. We can easily do it as follows:
sed 's/bla/BLA/3' myfile.txt
And we get:
This is the first line bla bla BLA This is the second line bla bla BLA This is the third line bla bla BLA some other text is here This is Predictive Hacks a Data Science blog

As we can see, only the third occurrence of “bla” of each line was replaced with the “BLA”.
The use of “&”
We can call the matched pattern with the use of “&” symbol. Let’s say, that we want to enclose the first numbers of the eg.csv into parenthesis. Let’s see how we can do it.
sed 's/^[0-9]\{1,2\}/(&)/g' eg.csvAnd we get:
ID,Name,Dept,Gender (1),George,DS,M (2),Billy,DS,M (3),Nick,IT,M (4),George,IT,M (5),Nikki,HR,F (6),Claudia,HR,F (7),Maria,Sales,F (8),Jimmy,Sales,M (9),Jane,Marketing,F (10),George,DS,M
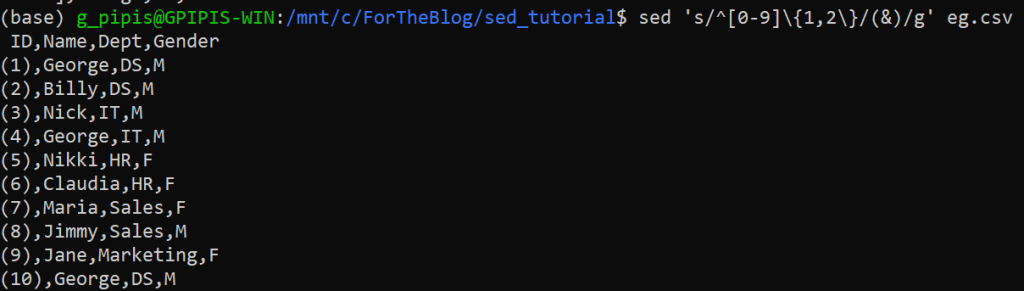
Explanation: The “^[0-9]\{1,2\}” part searches for any line which starts with 1 or 2 digits. Then, the matched text is denoted by “&”, so the “(&)” means to enclosed the first 1 to 2 digits into a parenthesis.
Multiple Commands
We can run multiple commands using the “-e” flag. Let’s say, that we would like to replace the “This” with “That” and the “is” with the “was” , in the same command.
sed -e 's/This/That/g' -e 's/is/was/g' myfile.txt
And we get:
That was the first line bla bla bla That was the second line bla bla bla That was the third line bla bla bla some other text was here That was Predictive Hacks a Data Science blog

Specifying a Range of Lines
We can specify a range of lines for the sed command. More particularly, we can specify:
- A single line with a single number.
- The last line with the “$” sign.
- Lines with a regular expression using the “/…/” notation
- A range of lines with the “,” symbol.
- An invert expression using the “!” symbol.
How to Replace a text in a Particular Line
Let’s say that we want to replace the “bla” with “BLA” in the third line only.
sed '3 s/bla/BLA/g' myfile.txt
And we get:
This is the first line bla bla bla This is the second line bla bla bla This is the third line BLA BLA BLA some other text is here This is Predictive Hacks a Data Science blog

Notice that the changes occurred in the third line only.
Printing Specific Lines
We can print specific lines. For example, let’s say that we want to print the first 5 lines.
sed -n '1,5 p' eg.csv
And we get:
ID,Name,Dept,Gender 1,George,DS,M 2,Billy,DS,M 3,Nick,IT,M 4,George,IT,M
Using the $ sign, we can print up to the last line. For example, let’s say that we want to get from the 5th line up to the end:
sed -n '5,$ p' eg.csv
And we get:
4,George,IT,M 5,Nikki,HR,F 6,Claudia,HR,F 7,Maria,Sales,F 8,Jimmy,Sales,M 9,Jane,Marketing,F 10,George,DS,M

Finally, using the !p notation we can invert the expression. For example, let’s say that we want to print all the lines apart from the first five.
sed -n '1,5 !p' eg.csv
And we get:
5,Nikki,HR,F 6,Claudia,HR,F 7,Maria,Sales,F 8,Jimmy,Sales,M 9,Jane,Marketing,F 10,George,DS,M
Printing Lines based on Regular Expression
Let’s say that I want to return all the lines that contain “bla” up until the first occurrence of “here“.
sed -n '/bla/ , /here/p' myfile.txt
And we get:
This is the first line bla bla bla This is the second line bla bla bla This is the third line bla bla bla some other text is here

Printing the Replaced Lines Only
We can print only the replaced lines by using the -n and -p flags. For example, we will replace the “DS” with the “Data Science” and we will return only the lines where there was a replacement.
sed -n 's/DS/Data Science/p' eg.csv
And we get:
1,George,Data Science,M 2,Billy,Data Science,M 10,George,Data Science,M

Deleting Lines
We can “delete” lines with the -d flag. When we say deleting, we mean that the lines will not be printed. Do not worry about your original file, it will not be affected. Let’s say that I want to”delete”, i.e. to filter out, all lines that contain “bla“.
sed '/bla/d' myfile.txt
And we get:
some other text is here This is Predictive Hacks a Data Science blog

Replacing Single Characters with Single Characters
Similar to the UNIX “tr” command, we can replace single characters with single characters using the -y flag. We can replace many single characters at once using mapping. For example, let’s say that I want to change the lower case vowels to the upper case.
- a –> A
- e –> E
- i –> I
- o –> O
- u –> U
sed 'y/aeiou/AEIOU/' myfile.txt
And we get:
ThIs Is thE fIrst lInE blA blA blA ThIs Is thE sEcOnd lInE blA blA blA ThIs Is thE thIrd lInE blA blA blA sOmE OthEr tExt Is hErE ThIs Is PrEdIctIvE HAcks A DAtA ScIEncE blOg

As we can see, all the vowels are in the upper case.
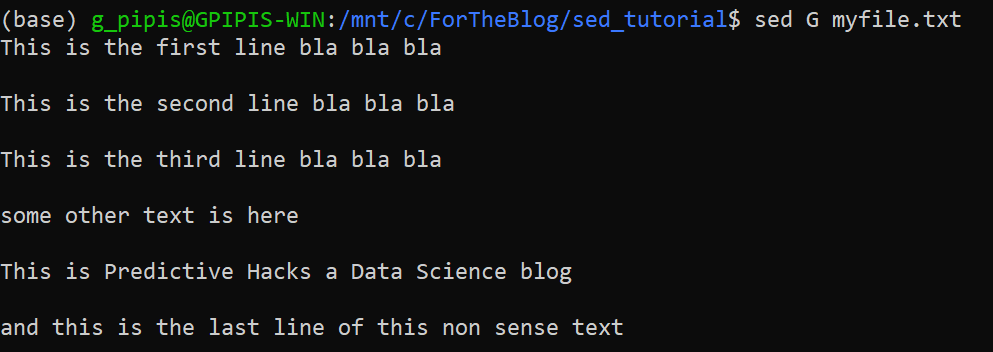
Adding a Blank Line After Each Line
We can insert a blank line after each line as follows:
$ sed G myfile.txt
And we get:
This is the first line bla bla bla This is the second line bla bla bla This is the third line bla bla bla some other text is here This is Predictive Hacks a Data Science blog and this is the last line of this non sense text
How to Delete Blank Lines
In the previous example, we added blank lines. Let’s see how we can remove blank lines using sed.
sed G myfile.txt | sed '/^$/d'
And we get:
This is the first line bla bla bla This is the second line bla bla bla This is the third line bla bla bla some other text is here This is Predictive Hacks a Data Science blog and this is the last line of this non sense text

The Takeaway
sed is a strong tool for processing text files and is a competitive technical skill for Data Scientists and Data Engineers. It enables us to do a basic data cleansing and some checks without having to load the files in memory using R or Python. If you found interesting the sed tutorial, you may like that awk tutorial too. Stay tuned.


