

In this post, we will work with the TensorFlow tutorial where we will try to go deeper by showing:
- How to start with a pandas data frame instead of a TensorFlow datasets
- How to get the Users’ and Items’ Embeddings
- How to find the expected score for every item for each user
- How to make recommendations for each user
- How to find similar items
- How to save and load the TensorFlow model
Preprocess the Data
We will work with the MovieLens dataset, collected by the GroupLens Research Project at the University of Minnesota. Our goal is to build a model that suggests movies to users. We will keep the user-item pairs where the rating is above 3 and this is because we would like to recommend movies that the user is likely to watch but also like.
import pandas as pd
# load the rating data
columns = ['user_id', 'item_id', 'rating', 'timestamp']
ratings = pd.read_csv('ml-100k/u.data', sep='\t', names=columns)
ratings.head()
# load the movies data
columns = ['item_id', 'movie title', 'release date', 'video release date', 'IMDb URL', 'unknown', 'Action', 'Adventure',
'Animation', 'Childrens', 'Comedy', 'Crime', 'Documentary', 'Drama', 'Fantasy', 'Film-Noir', 'Horror',
'Musical', 'Mystery', 'Romance', 'Sci-Fi', 'Thriller', 'War', 'Western']
movies = pd.read_csv('ml-100k/u.item', sep='|', names=columns, encoding='latin-1')
movies = movies[['item_id', 'movie title']]
movies.head()

# join the ratings with the movies ratings = pd.merge(ratings, movies, on='item_id') # keep only moviews with a rating greater than 3 ratings = ratings[ratings.rating>3] # keep only the user id and the movie title columns ratings = ratings[['movie title', 'user_id']].reset_index(drop=True) ratings
# save to a csv file
ratings.to_csv('ratings.csv', index=False)
movies.to_csv('movies.csv', index=False)
Build the Model
The idea is to build a retrieval model using user and item embeddings. We will work with the TensorFlow-recommenders library.
!pip install -q tensorflow-recommenders
from typing import Dict, Text import numpy as np import pandas as pd import tensorflow as tf import tensorflow_recommenders as tfrs
Since we installed the tensorflow-recommenders on Colab, we will load the ratings.csv and movies.csv that we generated in the previous step.
# read the csv files as pandas data frames
ratings_df = pd.read_csv('ratings.csv')
movies_df = pd.read_csv('movies.csv')
ratings_df.rename(columns = {'movie title': 'movie_title'}, inplace=True)
movies_df.rename(columns = {'movie title': 'movie_title'}, inplace=True)
Now, we will convert the pandas data frames to TensorFlow datasets.
# convert them to tf datasets ratings = tf.data.Dataset.from_tensor_slices(dict(ratings_df)) movies = tf.data.Dataset.from_tensor_slices(dict(movies_df))
Let’s have a look at our data:
# get the first rows of the movies dataset for m in movies.take(5): print(m)
{'item_id': <tf.Tensor: shape=(), dtype=int64, numpy=1>, 'movie_title': <tf.Tensor: shape=(), dtype=string, numpy=b'Toy Story (1995)'>}
{'item_id': <tf.Tensor: shape=(), dtype=int64, numpy=2>, 'movie_title': <tf.Tensor: shape=(), dtype=string, numpy=b'GoldenEye (1995)'>}
{'item_id': <tf.Tensor: shape=(), dtype=int64, numpy=3>, 'movie_title': <tf.Tensor: shape=(), dtype=string, numpy=b'Four Rooms (1995)'>}
{'item_id': <tf.Tensor: shape=(), dtype=int64, numpy=4>, 'movie_title': <tf.Tensor: shape=(), dtype=string, numpy=b'Get Shorty (1995)'>}
{'item_id': <tf.Tensor: shape=(), dtype=int64, numpy=5>, 'movie_title': <tf.Tensor: shape=(), dtype=string, numpy=b'Copycat (1995)'>}# get the first rows of the ratings dataset for r in ratings.take(5): print(r)
{'movie_title': <tf.Tensor: shape=(), dtype=string, numpy=b'Kolya (1996)'>, 'user_id': <tf.Tensor: shape=(), dtype=int64, numpy=226>}
{'movie_title': <tf.Tensor: shape=(), dtype=string, numpy=b'Kolya (1996)'>, 'user_id': <tf.Tensor: shape=(), dtype=int64, numpy=306>}
{'movie_title': <tf.Tensor: shape=(), dtype=string, numpy=b'Kolya (1996)'>, 'user_id': <tf.Tensor: shape=(), dtype=int64, numpy=296>}
{'movie_title': <tf.Tensor: shape=(), dtype=string, numpy=b'Kolya (1996)'>, 'user_id': <tf.Tensor: shape=(), dtype=int64, numpy=34>}
{'movie_title': <tf.Tensor: shape=(), dtype=string, numpy=b'Kolya (1996)'>, 'user_id': <tf.Tensor: shape=(), dtype=int64, numpy=271>}Let’s keep the basic features of our model.
# Select the basic features.
ratings = ratings.map(lambda x: {
"movie_title": x["movie_title"],
"user_id": x["user_id"]
})
movies = movies.map(lambda x: x["movie_title"])
Build vocabularies to convert user ids and movie titles into integer indices for embedding layers
For our model, we need to assign indices for the unique users and movies. Note that we add an extra index for the unknown users and movies respectively.
user_ids_vocabulary = tf.keras.layers.IntegerLookup(mask_token=None) user_ids_vocabulary.adapt(ratings.map(lambda x: x["user_id"])) movie_titles_vocabulary = tf.keras.layers.StringLookup(mask_token=None) movie_titles_vocabulary.adapt(movies)
Create the Model
We will work with the tfrs.Model by implementing the compute_loss method.
class MovieLensModel(tfrs.Model):
# We derive from a custom base class to help reduce boilerplate. Under the hood,
# these are still plain Keras Models.
def __init__(
self,
user_model: tf.keras.Model,
movie_model: tf.keras.Model,
task: tfrs.tasks.Retrieval):
super().__init__()
# Set up user and movie representations.
self.user_model = user_model
self.movie_model = movie_model
# Set up a retrieval task.
self.task = task
def compute_loss(self, features: Dict[Text, tf.Tensor], training=False) -> tf.Tensor:
# Define how the loss is computed.
user_embeddings = self.user_model(features["user_id"])
movie_embeddings = self.movie_model(features["movie_title"])
return self.task(user_embeddings, movie_embeddings)
We have to define the user_model and moview_model which are sequential models for generating the embeddings. Finally, the objective of the task is a retrieval model.
# Define user and movie models.
user_model = tf.keras.Sequential([
user_ids_vocabulary,
tf.keras.layers.Embedding(user_ids_vocabulary.vocabulary_size(), 64)
])
movie_model = tf.keras.Sequential([
movie_titles_vocabulary,
tf.keras.layers.Embedding(movie_titles_vocabulary.vocabulary_size(), 64)
])
# Define your objectives.
task = tfrs.tasks.Retrieval(metrics=tfrs.metrics.FactorizedTopK(
movies.batch(128).map(movie_model)
)
)
Fit the Model
The last step is to build the model, train it and make some predictions.
# Create a retrieval model. model = MovieLensModel(user_model, movie_model, task) model.compile(optimizer=tf.keras.optimizers.Adagrad(0.5)) # Train for 3 epochs. model.fit(ratings.batch(4096), epochs=3)
Make Predictions
Let’s make predictions for the user_id=42.
# Use brute-force search to set up retrieval using the trained representations.
index = tfrs.layers.factorized_top_k.BruteForce(model.user_model)
index.index_from_dataset(
movies.batch(100).map(lambda title: (title, model.movie_model(title))))
# Get some recommendations.
_, titles = index(np.array([42]))
print(f"Top 10 recommendations for user 42: {titles[0, :10]}")
Top 10 recommendations for user 42:
[b"Preacher's Wife, The (1996)"
b'Far From Home: The Adventures of Yellow Dog (1995)'
b'Santa Clause, The (1994)' b'Striptease (1996)'
b'Homeward Bound II: Lost in San Francisco (1996)'
b'Aristocats, The (1970)' b'Associate, The (1996)'
b'Swan Princess, The (1994)' b'Father of the Bride Part II (1995)'
b'Eye for an Eye (1996)']Get Users’ and Movies’ Embeddings
It is very useful to get and work with the users’ and movies’ embeddings since they can be used in several tasks. The embeddings are simply the weights of the model. Keep in mind that each embedding corresponds to a vocabulary value.
Users’ Embeddings
# get the users embeddings users_embdeddings = user_model.weights[1].numpy() # get the mapping of the user ids from the vocabulary users_idx_name = user_ids_vocabulary.get_vocabulary() # print the shape users_embdeddings.shape
(943, 64)Movies’ Embeddings
# get the movies embeddings movies_embdeddings = movie_model.weights[1].numpy() # get the mapping of the movie tiles from the vocabulary movie_idx_name = movie_titles_vocabulary.get_vocabulary() # print the shape of the movies embeddings movies_embdeddings.shape
(1665, 64)Note that we can get a specific embedding using the predict method as follows:
movie_model.predict(["Star Wars (1977)"])
1/1 [==============================] - 0s 275ms/step
array([[-0.16629432, 0.17870611, -0.26209885, 0.35331044, 0.30921447,
-0.23738807, 0.39384413, -0.07973698, 0.08024213, 0.39520767,
-0.46733057, -0.24467549, 0.19564332, -0.06281933, -0.2583185 ,
-0.25523886, -0.02148814, 0.20074879, -0.3568265 , 0.23197336,
0.21116029, -0.02405142, -0.21970779, -0.17397091, -0.13578957,
0.40819183, 0.22189239, -0.03745475, -0.3153276 , -0.23574194,
-0.06131107, -0.03642035, 0.2329314 , 0.01522365, 0.2002761 ,
0.01093197, -0.2641881 , 0.4224493 , 0.01203017, -0.29093683,
-0.3808443 , -0.10117595, 0.00327679, 0.17261043, 0.25872728,
0.03175502, -0.01068573, 0.29258794, -0.07371835, -0.16357234,
0.42200977, 0.06934218, -0.08999524, 0.00627236, 0.04357202,
-0.06979217, 0.12473913, 0.03120498, 0.2298355 , 0.02938793,
0.5080083 , -0.30276206, -0.08775371, -0.7890533 ]],
dtype=float32)Find Similar Movies Based on Movies Embeddings
At this step, we will return the pairs of the most similar movies. Of course, you can get the most similar movies for any specific movie.
from sklearn.metrics import pairwise_distances # get the cosine similarity of all pairs movies_similarity = 1-pairwise_distances(movies_embdeddings, metric='cosine') # get the upper triangle in order to take the unique pairs movies_similarity = np.triu(movies_similarity)
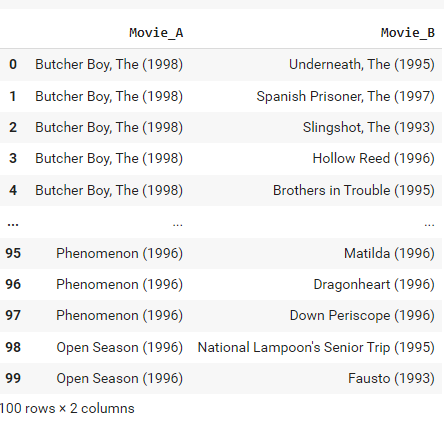
Get the pairs of the most similar movies with a threshold of cosine similarity greater than 0.8.
Movie_A = np.take(movie_idx_name, np.where((movies_similarity>0.8))[0])
Movie_B = np.take(movie_idx_name, np.where((movies_similarity>0.8))[1])
similar_movies = pd.DataFrame({'Movie_A':Movie_A, 'Movie_B':Movie_B})
similar_movies.head(100)
Get User’s Recommendations with Matrix Multiplication
Since we have built the user matrix and the movie matrix, we can multiply the two tables in order to get a score for each user for every movie.
# get the product of users and movies embeddings product_matrix = np.matmul(users_embdeddings, np.transpose(movies_embdeddings)) # get the shape of the product matrix product_matrix.shape
(943, 1665)In essence, the above matrix is the estimated user-item matrix. Let’s get the top 10 recommended movies for the user=42 using the matrix estimated user-item matrix.
# score of movies for user 42 user_42_movies = product_matrix[users_idx_name.index(42),:] # return the top 10 movies np.take(movie_idx_name, user_42_movies.argsort()[::-1])[0:10]
array(["Preacher's Wife, The (1996)",
'Far From Home: The Adventures of Yellow Dog (1995)',
'Santa Clause, The (1994)', 'Striptease (1996)',
'Homeward Bound II: Lost in San Francisco (1996)',
'Aristocats, The (1970)', 'Associate, The (1996)',
'Swan Princess, The (1994)', 'Father of the Bride Part II (1995)',
'Eye for an Eye (1996)'], dtype='<U81')As we can see, we got exactly the same results as above when we used the tfrs.layers.factorized_top_k.BruteForce.
If we want to exclude the already watched movies, we can work as follows.
seen_movies = ratings_df.query('user_id==42')['movie_title'].values
np.setdiff1d(np.take(movie_idx_name, user_42_movies.argsort()[::-1]), seen_movies, assume_unique=True)[0:10]
array(['Far From Home: The Adventures of Yellow Dog (1995)',
'Striptease (1996)',
'Homeward Bound II: Lost in San Francisco (1996)',
'Swan Princess, The (1994)', 'Eye for an Eye (1996)',
'Milk Money (1994)', 'Escape from L.A. (1996)',
'Dragonheart (1996)', 'Cool Runnings (1993)', 'Craft, The (1996)'],
dtype='<U81')Save and Load the Model
To deploy a model like this, we simply export the BruteForce layer we created above:
import tempfile
import os
# Export the query model.
with tempfile.TemporaryDirectory() as tmp:
path = os.path.join(tmp, "model")
# Save the index.
tf.saved_model.save(index, path)
# Load it back; can also be done in TensorFlow Serving.
loaded = tf.saved_model.load(path)
# Pass a user id in, get top predicted movie titles back.
scores, titles = loaded([42])
print(f"Recommendations: {titles[0][:10]}")
As expected, we get the same recommendations for user 42.
Recommendations: [b"Preacher's Wife, The (1996)"
b'Far From Home: The Adventures of Yellow Dog (1995)'
b'Santa Clause, The (1994)' b'Striptease (1996)'
b'Homeward Bound II: Lost in San Francisco (1996)'
b'Aristocats, The (1970)' b'Associate, The (1996)'
b'Swan Princess, The (1994)' b'Father of the Bride Part II (1995)'
b'Eye for an Eye (1996)']

