

Hugging Face has launched the auto train, which is a new way to automatically train, evaluate and deploy state-of-the-art Machine Learning models. It enables us to train custom machine learning models by simply uploading the data. Under the hood, it runs automatically different models and keeps the best ones. Finally, we use our models directly from the Hugging Face Hub. Currently, it supports the following tasks:
- Image Classification
- Text Classification
- Token Classification
- Question Answering
- Translation
- Summarization
- Text Regression
- Tabular Data Classification
- Tabular Data Regression
In this tutorial, we will work on a Text Classification example.
Text Classification with Hugging Face Auto Train
Let’s start building our text classification model using the Hugging Face Auto Train. You have to sign in to the Hugging Face. Then, you click on the “Create new project” button.

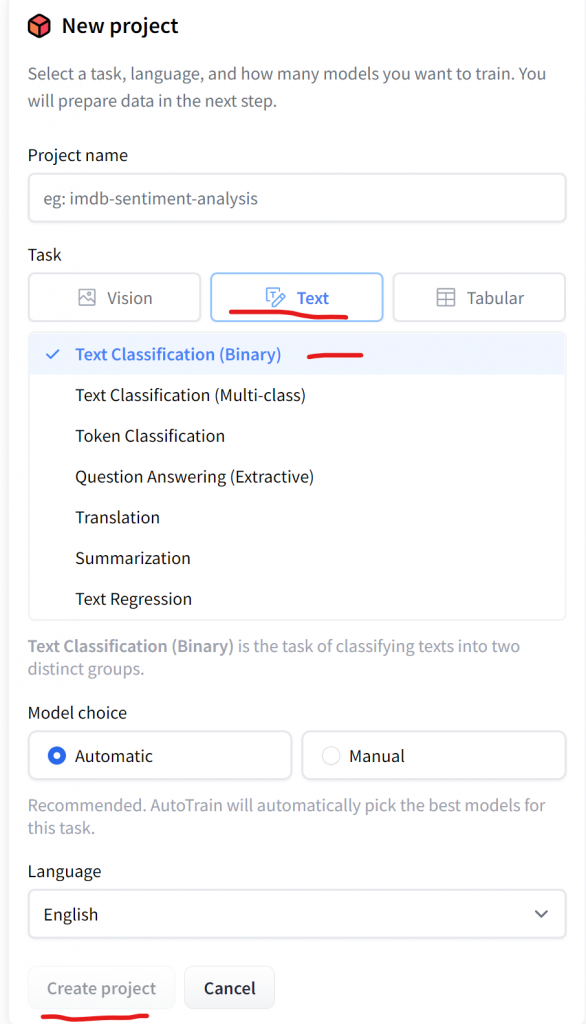
Then, you give the project name, and you choose a task. In our case, we will use a “Text” task and more particularly a “Text Classification (Binary)” and finally we click on the “Create Project“
Then, we can upload the .csv file of two columns, such as text and target.

For this example, I chose a dataset from hotel reviews. The file consists of two columns, the text and the target that takes two values, 0 (negative) or 1 (positive).
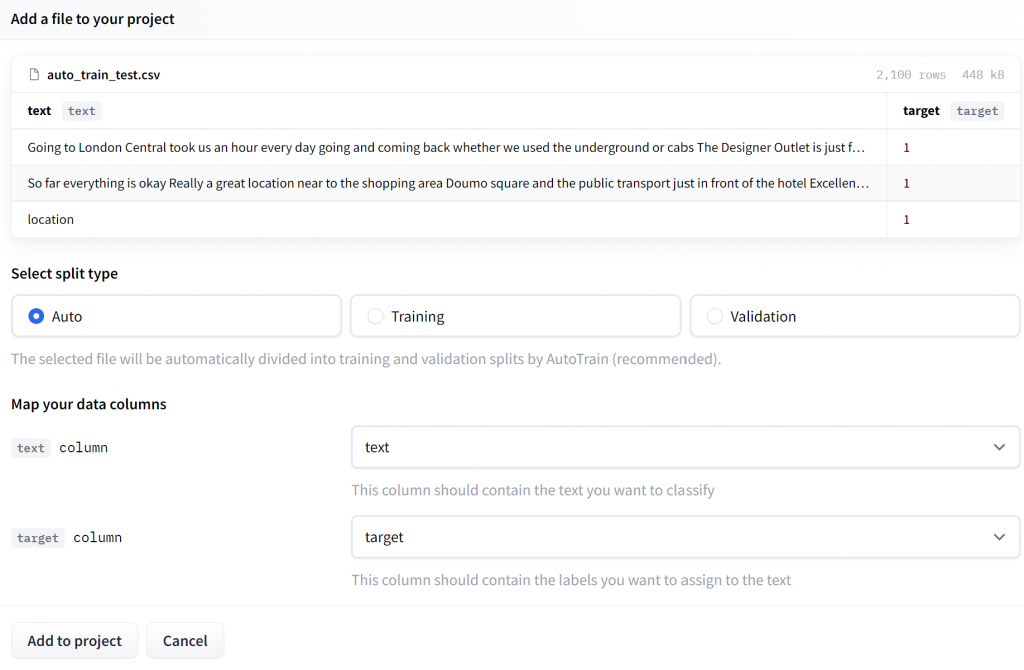
Note, that for the free version, the dataset must be less than 3000 rows! Once we upload the data, we click on “Add to project“. Then we are ready to train the model, by clicking on the “Go to trainings“.
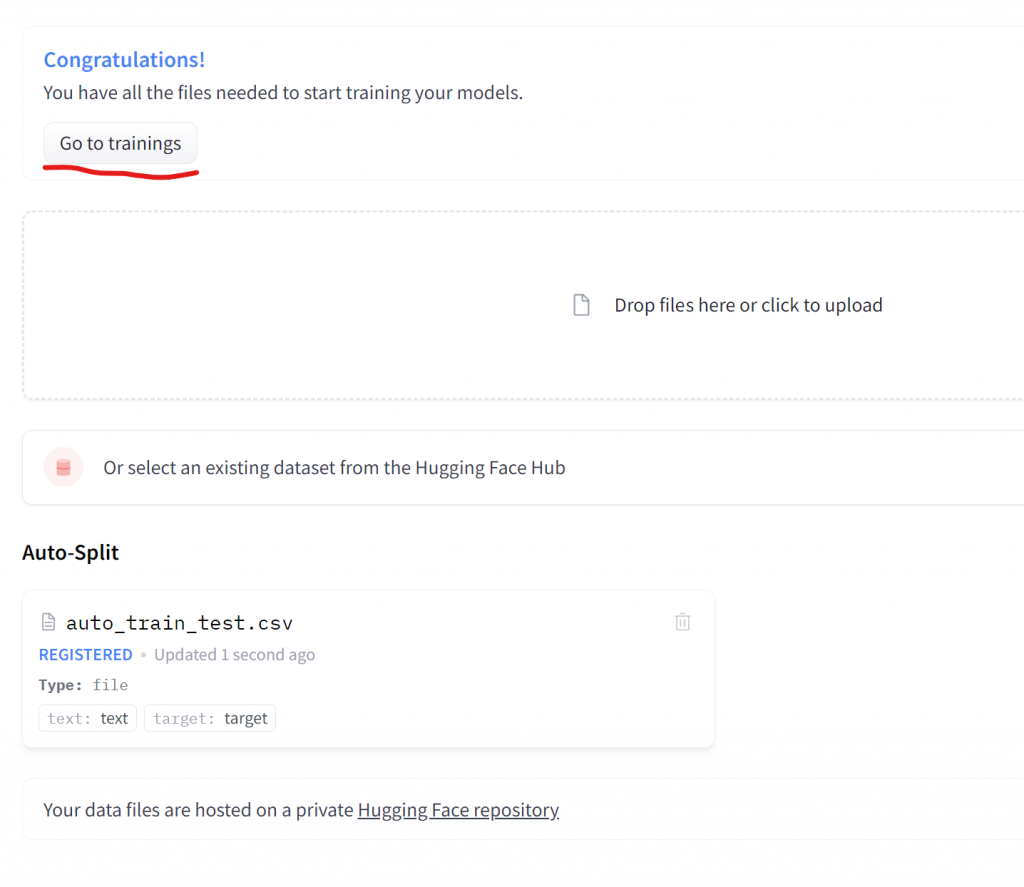
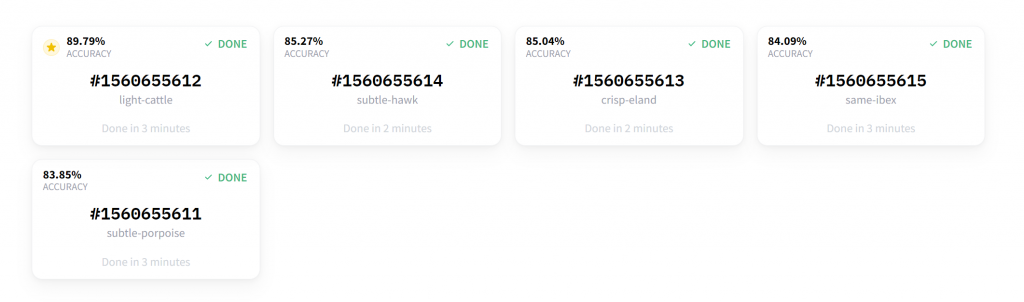
The free version allows us to train up to 5 models.

The 5 models run in parallel, and you can see their accuracy.
If we click on the model, we can see other metrics such as Precision, Recall, Auc, F1 and Loss.
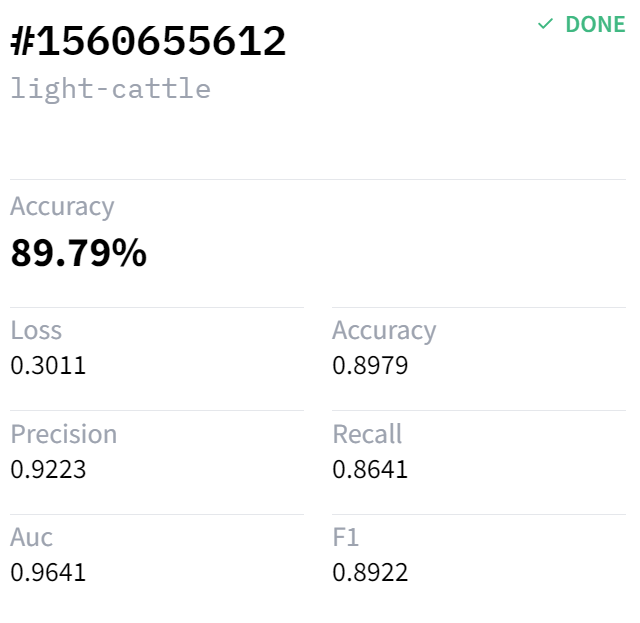
Or, if we go to the Metrics section, we can have a summary view of all models.

Make Predictions from the UI
When we are in the Metrics section, we can click on any Model ID. Let’s try the review “The hotel was amazing“.
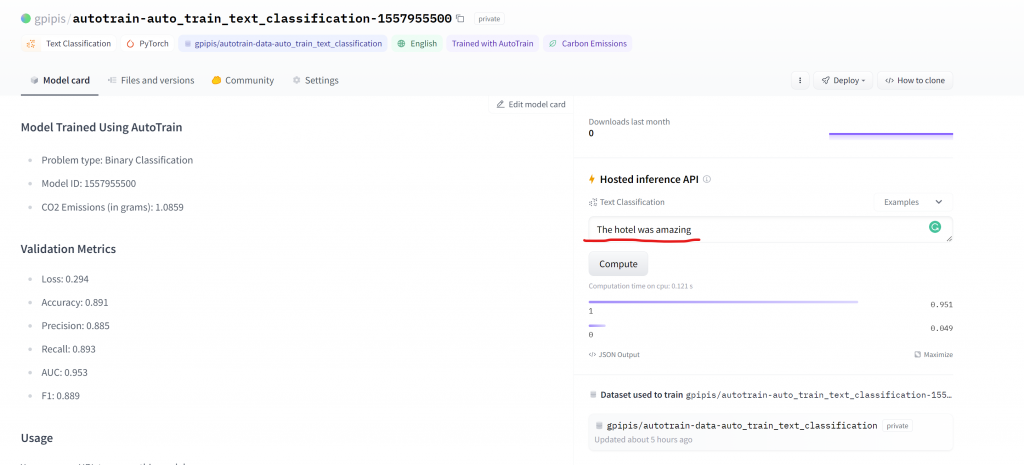
We got a label=1 which means positive with a probability of 95%.
Make Predictions with Python
On the bottom left, you can see a section called “Usage“, where it shows how to make curl and Python calls. We will need to just copy paste the Python API code snippet code.

In order to call the model from the Python API, we will need to create an use_auth_token. We should go to settings/tokens and create a new token for the auto_train.

Once we have created the access token, we can copy it and use it, as we will show below. Now, let’s move to Colab. We have to install the transformers library and then simply paste the code snippet that we copied above. For the use_aut_token, we will pass the Access Token that we generated earlier.
!pip install transformers
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("gpipis/autotrain-auto_train_text_classification-1557955500", use_auth_token='xxx')
tokenizer = AutoTokenizer.from_pretrained("gpipis/autotrain-auto_train_text_classification-1557955500", use_auth_token='xxx')
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
outputs
SequenceClassifierOutput(loss=None, logits=tensor([[-1.3991, 1.5701]], grad_fn=<AddmmBackward0>), hidden_states=None, attentions=None)The output returns the logits. If we want to get the probabilities of each class, we will need to use the softmax function as follows:
from torch import nn pt_predictions = nn.functional.softmax(outputs.logits, dim=-1) pt_predictions
tensor([[0.0488, 0.9512]], grad_fn=<SoftmaxBackward0>)Make Predictions with the Pipeline
We can make predictions using the pipelines as follows.
from transformers import pipeline
my_pipeline = pipeline(task="text-classification", model=model, tokenizer=tokenizer)
my_score = my_pipeline('The hotel was amazing')
my_score
[{'label': '1', 'score': 0.9511635303497314}]As we can see, we got the same results with the UI, meaning a label equal to 1 with a probability of 95%.
More about Transformers and Hugging Face?
- Mastering Sentence Transformers For Sentence Similarity
- How to Fine-Tune an NLP Regression Model with Transformers and HuggingFace
- How to Build an NLP Classification Model with Transformers on AWS SageMaker
- How to Fine-Tune an NLP Classification Model with Transformers and HuggingFace
- How to Paraphrase Documents using Transformers
- Answering Questions with Transformers
- Text Summarization with Transformers
- How to Change Column Names in HuggingFace Datasets
- How to Load CSV files as Huggingface Dataset


