
This tutorial will show you how to build content-based recommender systems in TensorFlow from scratch. For this example, we will work with ads and our KPI will be the “Clicks“. In other words, we would like to build a content-based recommender system for serving ads by considering as features the users’ attributes and the content of the ads. For the content of the ads, we will get the BERT embeddings.
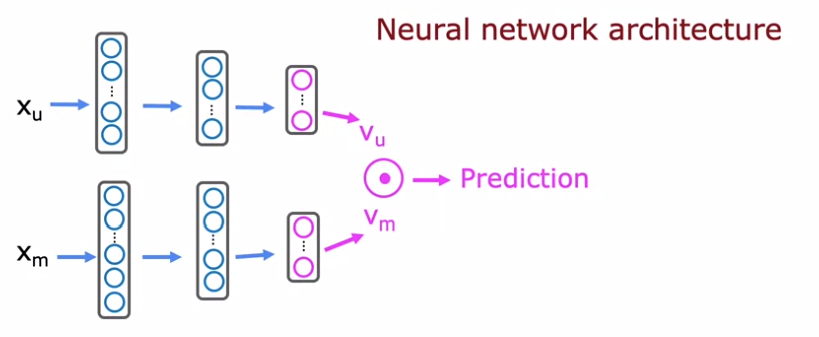
The architecture of the model will be two tower models, the user model, and the item model, concatenated with the dot product.
Load the Data and the Libraries
The data are from a Web Ad campaign. The available features are:
- The user attributes like
age,genderand so on. These columns start with the prefixatt_ - The KPI, where in our case is
clicked, taking values 0 or 1. - The content of the ad, which is a text column
- The ad ID
Load the Libraries
#!pip install --upgrade tensorflow_hub
#!pip install --upgrade tensorflow_text
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Model
from sklearn.feature_extraction.text import CountVectorizer
import tensorflow_hub as hub
import tensorflow_text as text # Imports TF ops for preprocessing.
pd.set_option("max_colwidth", 300)
Create a function to convert the text to BERT Embeddings
# Define the model
BERT_MODEL = "https://tfhub.dev/google/experts/bert/wiki_books/2"
# Choose the preprocessing that must match the model
PREPROCESS_MODEL = "https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3"
preprocess = hub.load(PREPROCESS_MODEL)
bert = hub.load(BERT_MODEL)
def text_to_emb(input_text):
input_text_lst = [input_text]
inputs = preprocess(input_text_lst)
outputs = bert(inputs)
return np.array((outputs['pooled_output'])).reshape(-1,)
Load the Data
# load the data
df = pd.read_csv("my_campaign.csv")
#define the KPI
kpi = 'clicked'
users_features = [col for col in df if col.startswith('att_')]
extra = ['text', 'message_id', kpi]
# convert the df to dummies
df = pd.concat([pd.get_dummies(df[users_features]), df[extra]], axis=1)
df.head()

In order to be more efficient, we will get the embeddings of the unique ads
# keep the unique messages that will be used for the predictions unique_messages = df.drop_duplicates(subset=['message_id']).sort_values(by='message_id').filter(regex='^text', axis=1) unique_messages_wit_ids = df.drop_duplicates(subset=['message_id','message_id']).sort_values(by='message_id').filter(regex='^text|message_id', axis=1) unique_messages_wit_ids.reset_index(drop=True, inplace=True) unique_messages_wit_ids['embeddings'] = unique_messages_wit_ids['text'].apply(lambda x:text_to_emb(x))
Train and Test Dataset
We will go with 80% train and 20% test dataset.
# create the train and test dataset train=df.sample(frac=0.8,random_state=5) test=df.drop(train.index) train.reset_index(drop=True, inplace= True) test.reset_index(drop=True, inplace= True) items_train = np.array(train.merge(unique_messages_wit_ids, how='inner', on='message_id')['embeddings'].values.tolist()) items_test = np.array(test.merge(unique_messages_wit_ids, how='inner', on='message_id')['embeddings'].values.tolist())
Build the Model
We will build three models, the user model, the item model, and the concatenated model. The user and the item model are Neural Network models of many layers. The models can have a different architecture, but the final layer must be of the same dimension in order to concatenate them using the dot product. In our case, the final layer of each model consists of 32 units.
num_user_features = train.filter(regex='^att_').shape[1]
num_item_features =items_train.shape[1]
# the model
num_outputs = 32
tf.random.set_seed(1)
user_NN = tf.keras.models.Sequential([
tf.keras.layers.Dense(128,activation='relu'),
#tf.keras.layers.Dropout(0.5),
#tf.keras.layers.Dense(64,activation='relu'),
#tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(num_outputs)
])
item_NN = tf.keras.models.Sequential([
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(64,activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(num_outputs)
])
# create the user input and point to the base network
input_user = tf.keras.layers.Input(shape=(num_user_features))
vu = user_NN(input_user)
vu = tf.linalg.l2_normalize(vu, axis=1)
# create the item input and point to the base network
input_item = tf.keras.layers.Input(shape=(num_item_features))
vm = item_NN(input_item)
vm = tf.linalg.l2_normalize(vm, axis=1)
# compute the dot product of the two vectors vu and vm
output_dot = tf.keras.layers.Dot(axes=1)([vu, vm])
output = tf.keras.layers.Dense(1,activation='sigmoid' )(output_dot)
# specify the inputs and output of the model
model = Model([input_user, input_item], output)
model.summary()
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 63)] 0 []
input_2 (InputLayer) [(None, 768)] 0 []
sequential (Sequential) (None, 32) 12320 ['input_1[0][0]']
sequential_1 (Sequential) (None, 32) 108768 ['input_2[0][0]']
tf.math.l2_normalize (TFOpLamb (None, 32) 0 ['sequential[0][0]']
da)
tf.math.l2_normalize_1 (TFOpLa (None, 32) 0 ['sequential_1[0][0]']
mbda)
dot (Dot) (None, 1) 0 ['tf.math.l2_normalize[0][0]',
'tf.math.l2_normalize_1[0][0]']
dense_5 (Dense) (None, 1) 2 ['dot[0][0]']
==================================================================================================
Total params: 121,090
Trainable params: 121,090
Non-trainable params: 0
__________________________________________________________________________________________________Train the model
tf.random.set_seed(1)
cost_fn = tf.keras.losses.BinaryCrossentropy()
opt = keras.optimizers.Adam(learning_rate=0.01)
model.compile(optimizer=opt,
loss=cost_fn)
callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=3)
tf.random.set_seed(1)
model.fit([train.filter(regex='^att_').values, items_train], train[kpi].values, epochs=20,
batch_size=16, validation_split=0.1, callbacks=[callback] )
Make Predictions
# keep the unique messages and their corresponding embeddings
sorted_msg_ids = sorted(unique_messages_wit_ids['message_id'].values)
unique_messages_vectors = np.array(unique_messages_wit_ids['embeddings'].values.tolist())
preds = []
for i in range(test.shape[0]):
temp_pred = model.predict([np.tile(test.filter(regex='^att_').values[i], (unique_messages_vectors.shape[0],1)), unique_messages_vectors]).argmax()
preds.append(sorted_msg_ids[temp_pred])
Make Predictions with Matrix Multiplication
Note that we have built the user and the item model. By taking the product of those two models and then taking into account the constant and the beta of the sigmoid function, we will be able to calculate the probabilities.
message_matrix = model_m.predict(unique_messages_vectors) user_matrix = model_u.predict(test.filter(regex='^att_').values) user_item_matrix = pd.DataFrame(np.matmul(user_matrix, np.transpose(message_matrix))) # apply the sigmoid function with the weights and the bias from the last layer tmp = (user_item_matrix.values*model.layers[-1].get_weights()[0])+model.layers[-1].get_weights()[1] user_item_matrix = pd.DataFrame(1/(1 + np.exp(-tmp))) user_item_matrix.columns = sorted(train.message_id.unique())
More tutorials related to recommendations?
- Spelling Recommender with NLTK
- How to run Recommender Systems in Python
- Topic Modelling with NMF in Python
- How to Build an Autocorrect in Python
- A Tutorial about Market Basket Analysis in Python
- Item-Based Collaborative Filtering in Python
- Market Basket Analysis and Association Rules from Scratch
- Get Started with TensorFlow Recommenders and Matrix Factorization
- Content-Based Recommender Systems with TensorFlow Recommender



2 thoughts on “Content-Based Recommender Systems in TensorFlow and BERT Embeddings”
Hi where to get the data?
Sorry but I cannot share the data